

In this guide, you will explore Kubernetes architecture inside-out. In this illustrated guide, I break down every Kubernetes component, from the control plane to the kubelet, showing you how the Kubernetes cluster really works.
So if you are looking to:
- Understand the architecture of Kubernetes
- Grasp the fundamental concepts underlying Kubernetes components.
- Learn about Each Kubernetes component in detail
- Explore the workflows that connect these components
Then you will find this Kubernetes architecture guide invaluable.
What is Kubernetes Architecture?
The following Kubernetes architecture diagram shows all the components of the Kubernetes cluster and how external systems connect to the Kubernetes cluster.
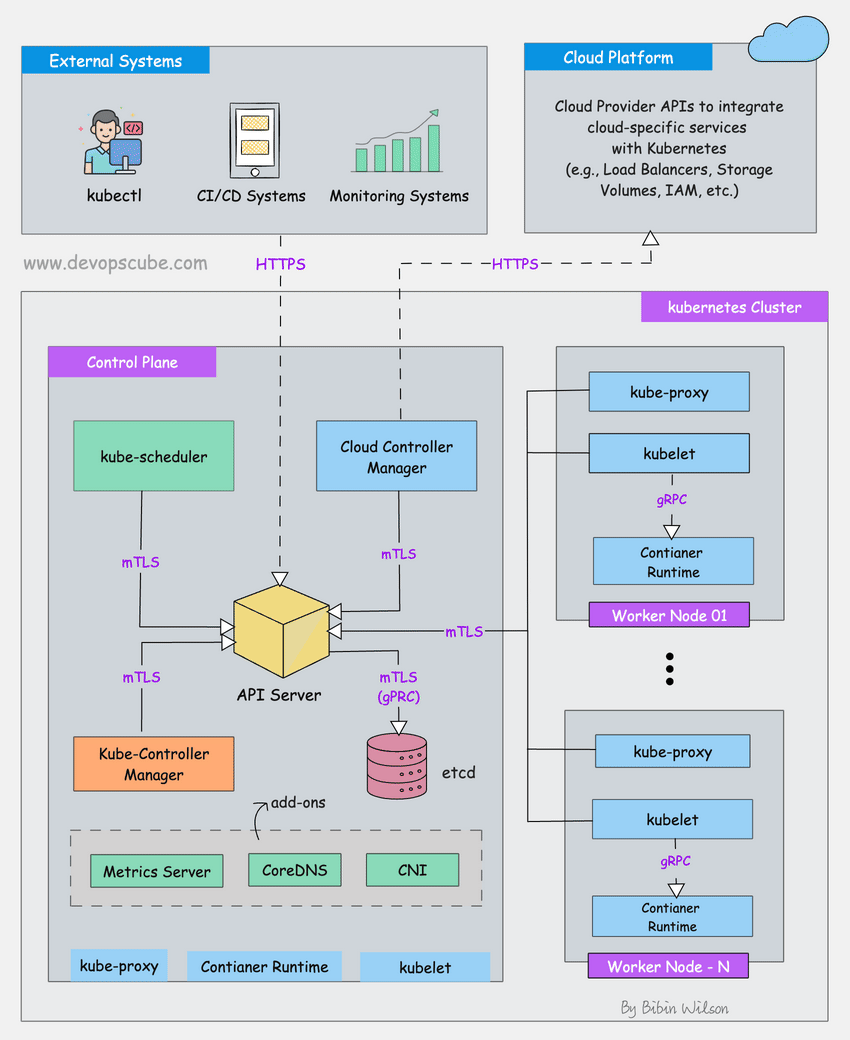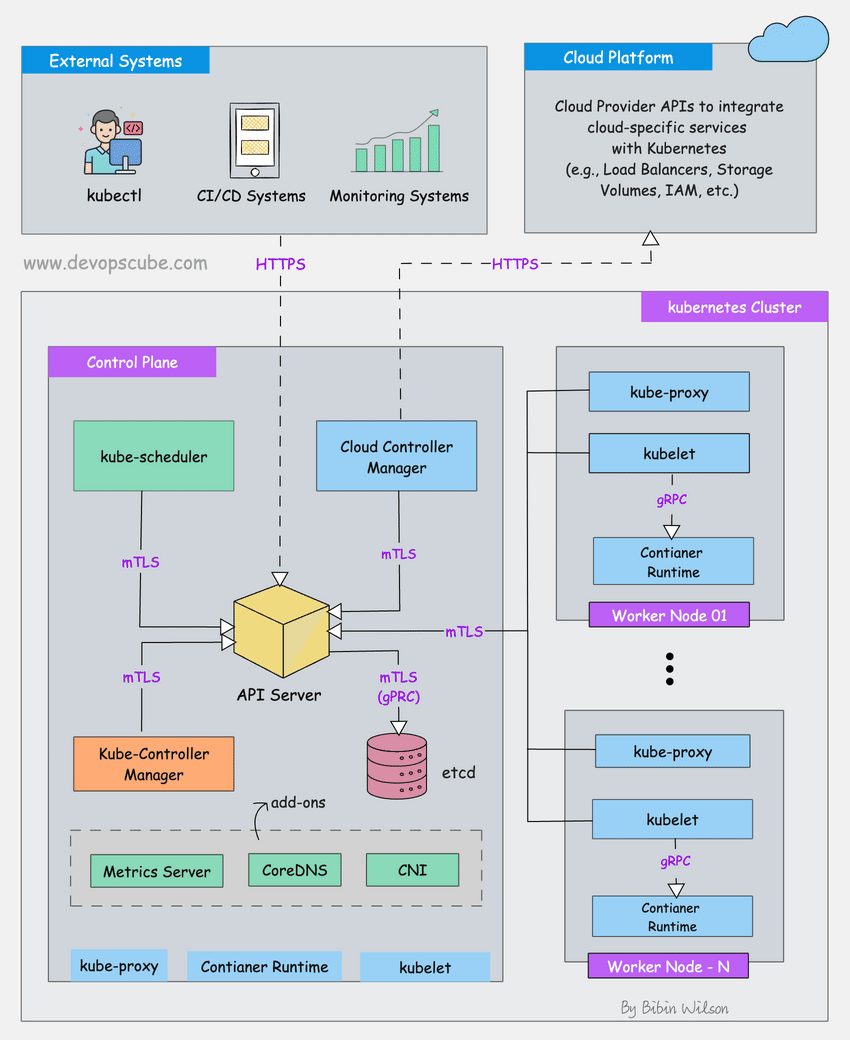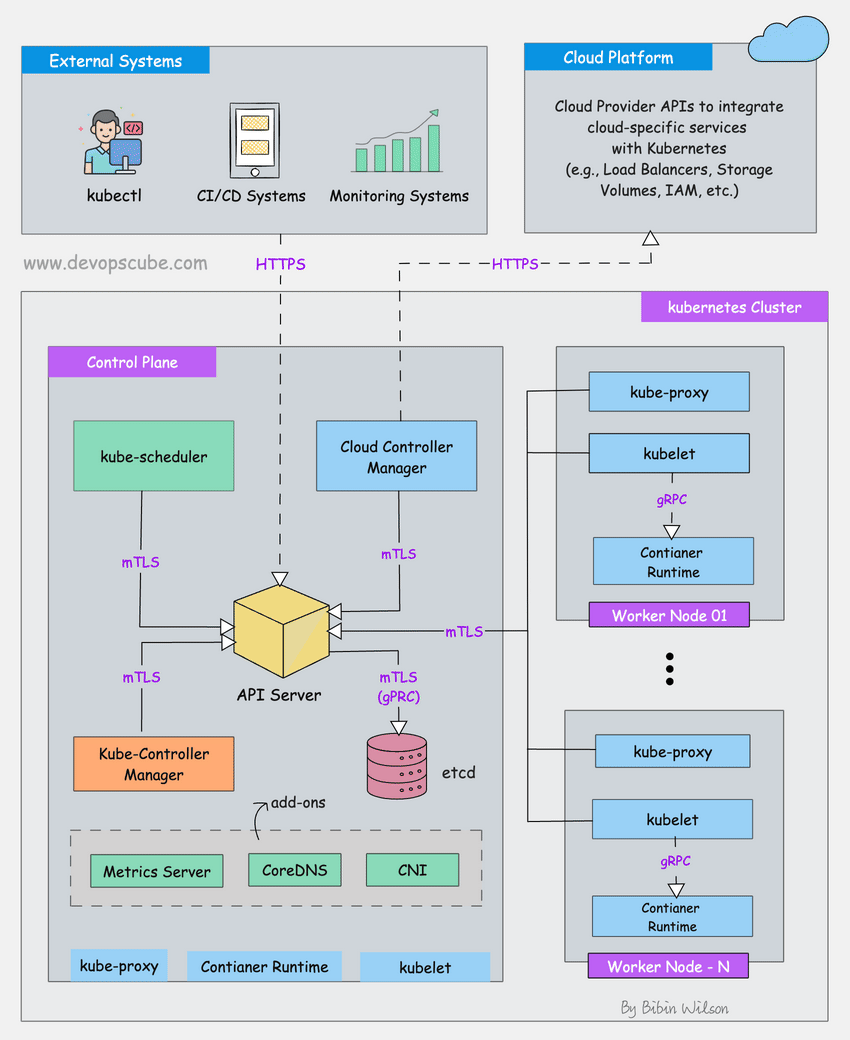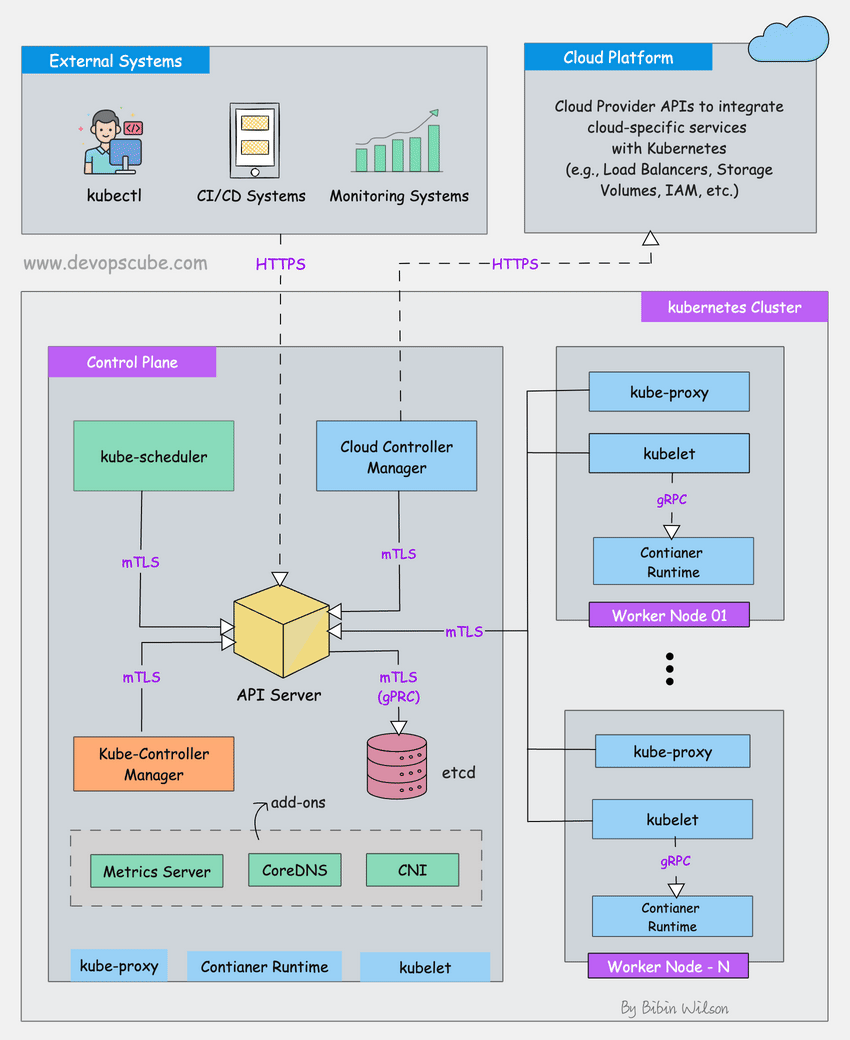
The first and foremost thing you should understand about Kubernetes is, that it is a distributed system. Meaning, it has multiple components spread across different servers over a network. These servers could be Virtual machines or bare metal servers. We call it a Kubernetes cluster.
A Kubernetes cluster consists of control plane nodes and worker nodes.
Control Plane
The control plane is responsible for container orchestration and maintaining the desired state of the cluster. It has the following components.
- kube-apiserver
- etcd
- kube-scheduler
- kube-controller-manager
- cloud-controller-manager
A cluster can have one or more control plane nodes.
Worker Node
The Worker nodes are responsible for running containerized applications. The worker Node has the following components.
- kubelet
- kube-proxy
- Container runtime
Now lets deep dive in to each of these components.
Kubernetes Control Plane Components
First, let's take a look at each control plane component and the important concepts behind each component.
1. kube-apiserver
The kube-apiserver is the central hub of the Kubernetes cluster that exposes the Kubernetes API. It is highly scalable and can handle large number of concurrent requests.
End users, and other cluster components, talk to the cluster via the API server. Very rarely monitoring systems and third-party services may talk to API servers to interact with the cluster.
So when you use kubectl to manage the cluster, at the backend you are actually communicating with the API server through HTTP REST APIs over TLS.
Also, the communication between the API server and other components in the cluster happens over TLS to prevent unauthorized access to the cluster.
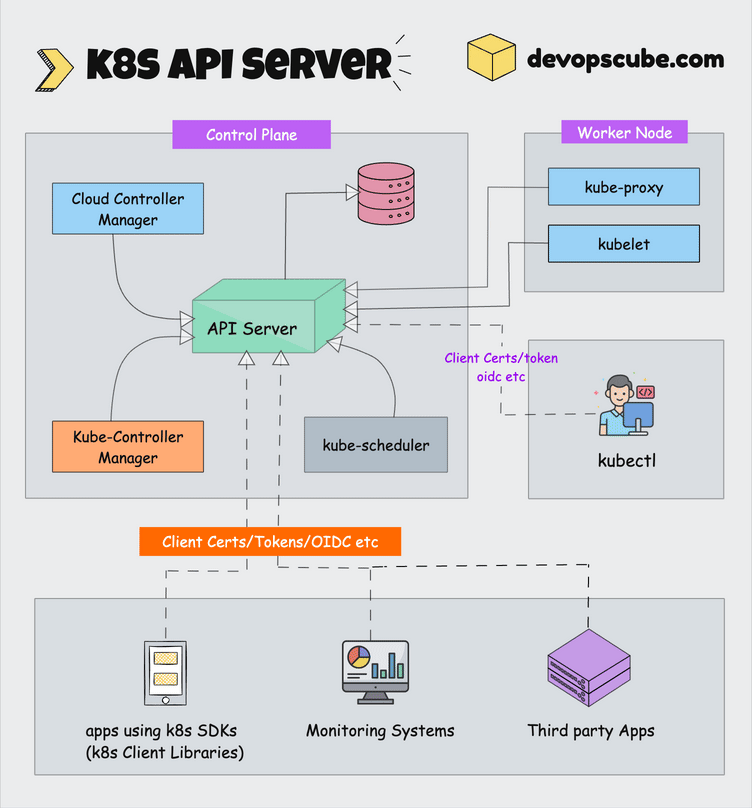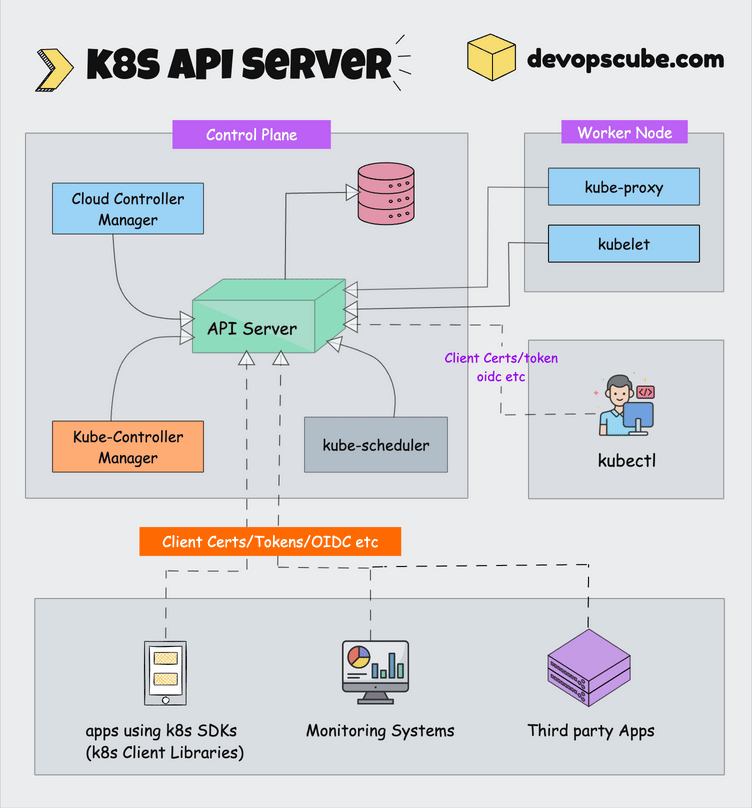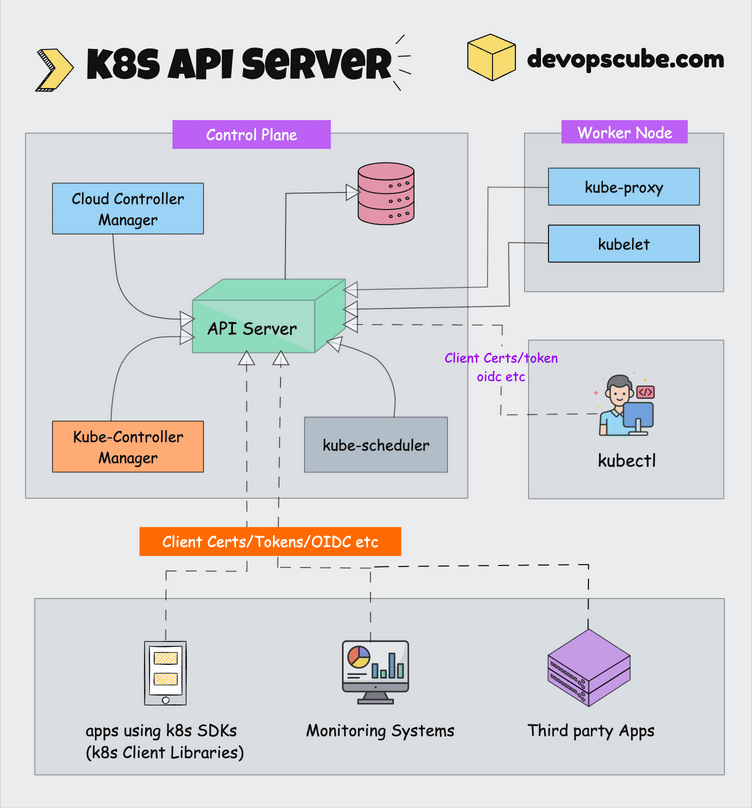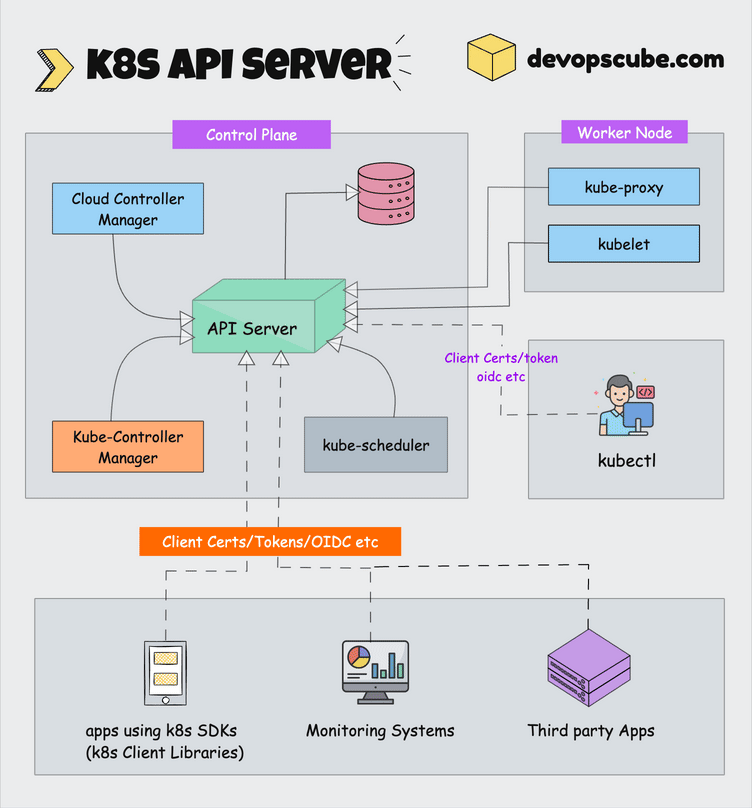
Kubernetes api-server is responsible for the following.
- API management: Exposes the cluster API endpoint and handles all API requests. The API is version and it supports multiple API versions simultaneously.
- Authentication (Using client certificates, bearer tokens, and HTTP Basic Authentication) and Authorization (ABAC and RBAC evaluation)
- Processing API requests and validating data for the API objects like pods, services, etc. (Validation and Mutation Admission controllers)
- the API server coordinates all the processes between the control plane and worker node components.
- API server also contains an aggregation layer which allows you to extend Kubernetes API to create custom API resources and controllers.
- The only component that the kube-apiserver initiates a connection to is the etcd component. All the other components connect to the API server.
- The API server also supports watching resources for changes. For example, clients can establish a watch on specific resources and receive real-time notifications when those resources are created, modified, or deleted.
- Each component (Kubelet, scheduler, controllers) independently watches the API server to figure out what it needs to do.
Also the api-server has a built-in apiserver proxy.
It is part of the API server process. It has a built-in proxy that forwards requests to cluster resources. This is primarily meant for administrative and debugging purposes and not for exposing applications outside the cluster.
2. etcd
Kubernetes is a distributed system and it needs an efficient distributed database like etcd that supports its distributed nature. It acts as the single source of truth for the cluster. All Kubernetes objects, configurations, and metadata are stored here.
etcd is an open-source strongly consistent, distributed key-value store. So what does it mean?
- Strongly consistent: If an update is made to a node, strong consistency will ensure it gets updated to all the other nodes in the cluster immediately. Also if you look at CAP theorem, achieving 100% availability with strong consistency and Partition Tolerance is impossible.
- Distributed: etcd is designed to run on multiple nodes as a cluster without sacrificing consistency.
- Key Value Store: A nonrelational database that stores data as keys and values. It also exposes a key-value API. The datastore is built on top of BboltDB which is a fork of BoltDB.
etcd uses raft consensus algorithm for strong consistency and availability. It works in a leader-member fashion for high availability and to withstand node failures.
So, how does etcd work with Kubernetes?
To put it simply, when you use kubectl to get kubernetes object details, you are getting it from etcd. Also, when you deploy an object like a pod, an entry gets created in etcd.
In a nutshell, here is what you need to know about etcd.
- etcd stores all configurations, states, and metadata of Kubernetes objects (pods, secrets, daemonsets, deployments, configmaps, statefulsets, etc).
etcdallows a client to subscribe to events usingWatch()API . Kubernetes api-server uses the etcd’s watch functionality to track the change in the state of an object.- etcd exposes key-value API using gRPC. Also, the gRPC gateway is a RESTful proxy that translates all the HTTP API calls into gRPC messages. This makes it an ideal database for Kubernetes.
- etcd stores all objects under the /registry directory key in key-value format. For example, information on a pod named Nginx in the default namespace can be found under /registry/pods/default/nginx
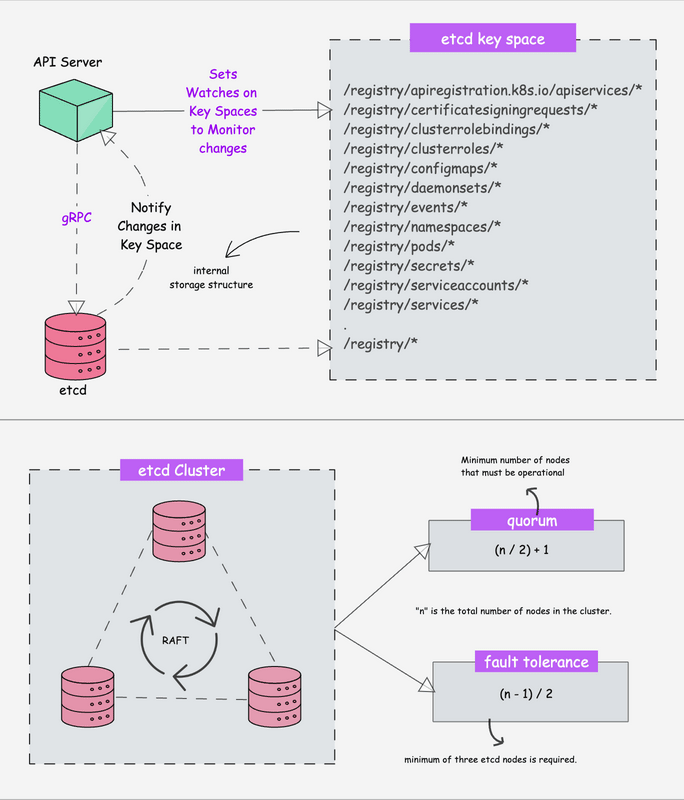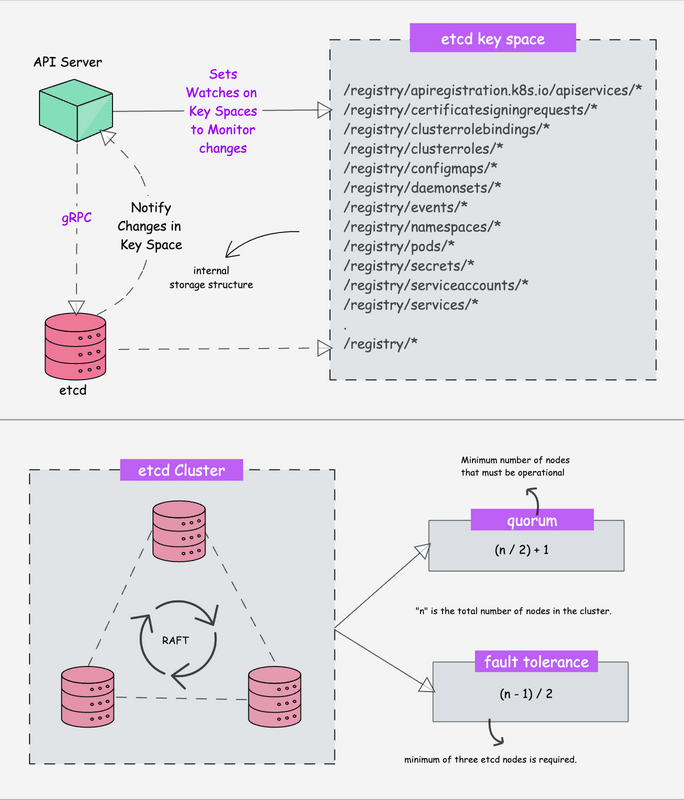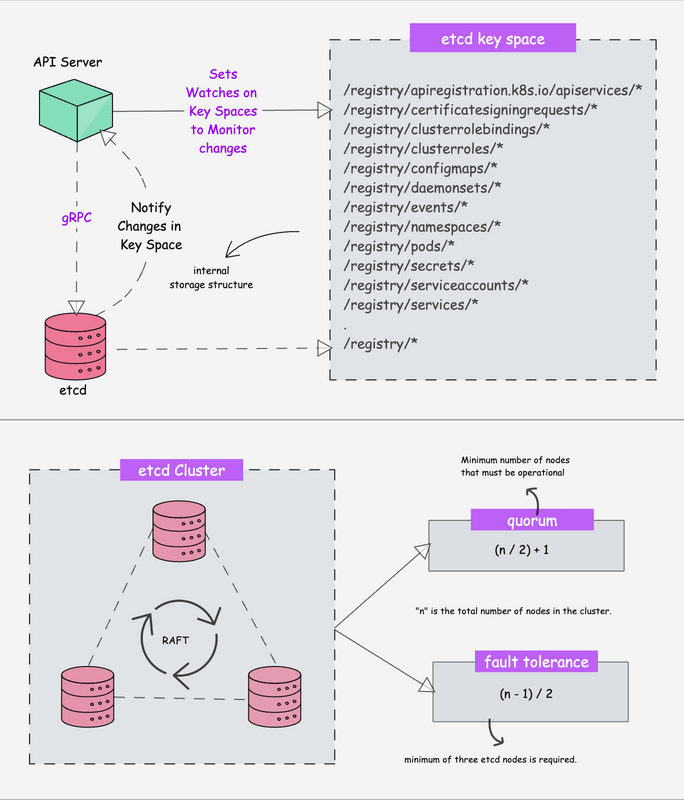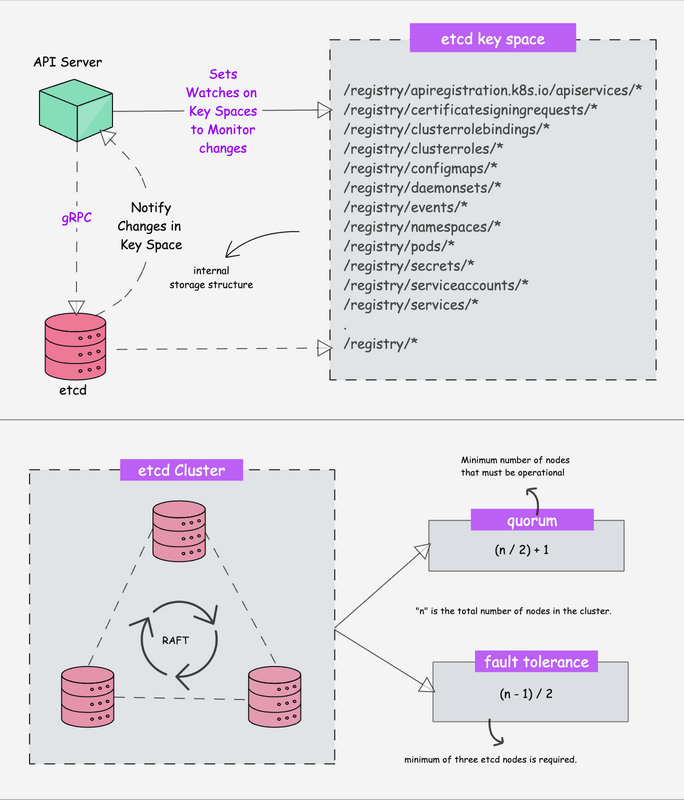
Also, etcd it is the only Statefulset component in the control plane. In kubeadm-based clusters, it typically runs as a static Pod managed by the kubelet.
3. kube-scheduler
The kube-scheduler is responsible for scheduling Kubernetes pods on worker nodes.
When you deploy a pod, you specify the pod requirements such as CPU, memory, affinity, taints or tolerations, priority, persistent volumes (PV), etc. The scheduler's primary task is to identify the create request and choose the best node for a pod that satisfies the requirements.
The following image shows a high-level overview of how the scheduler works.
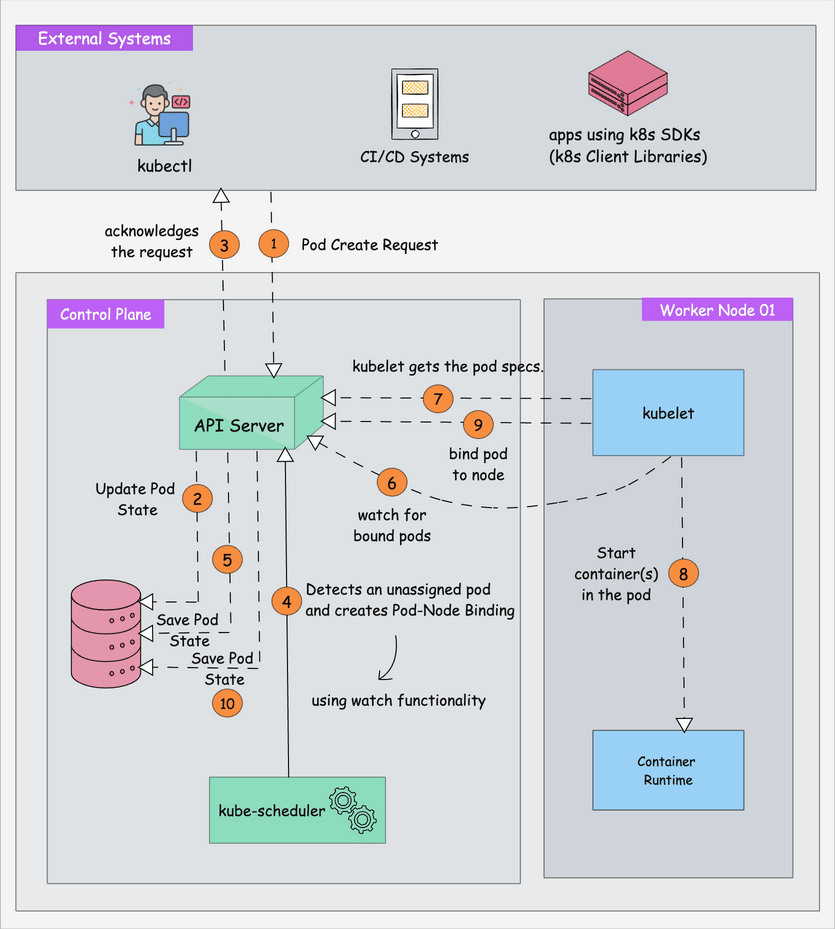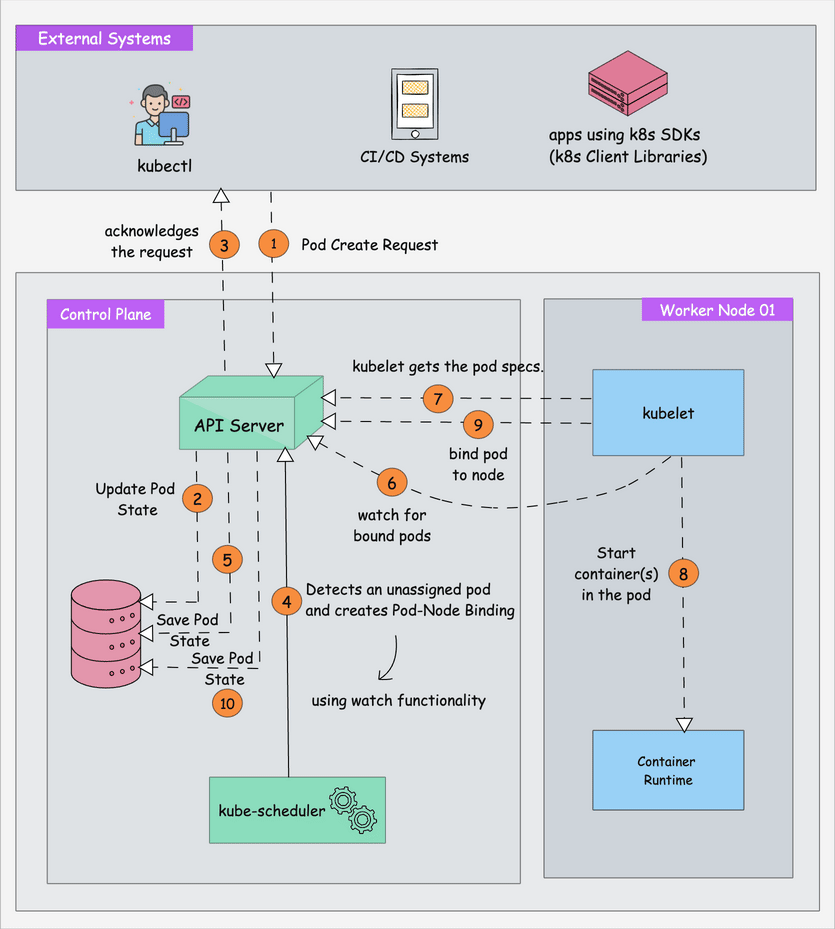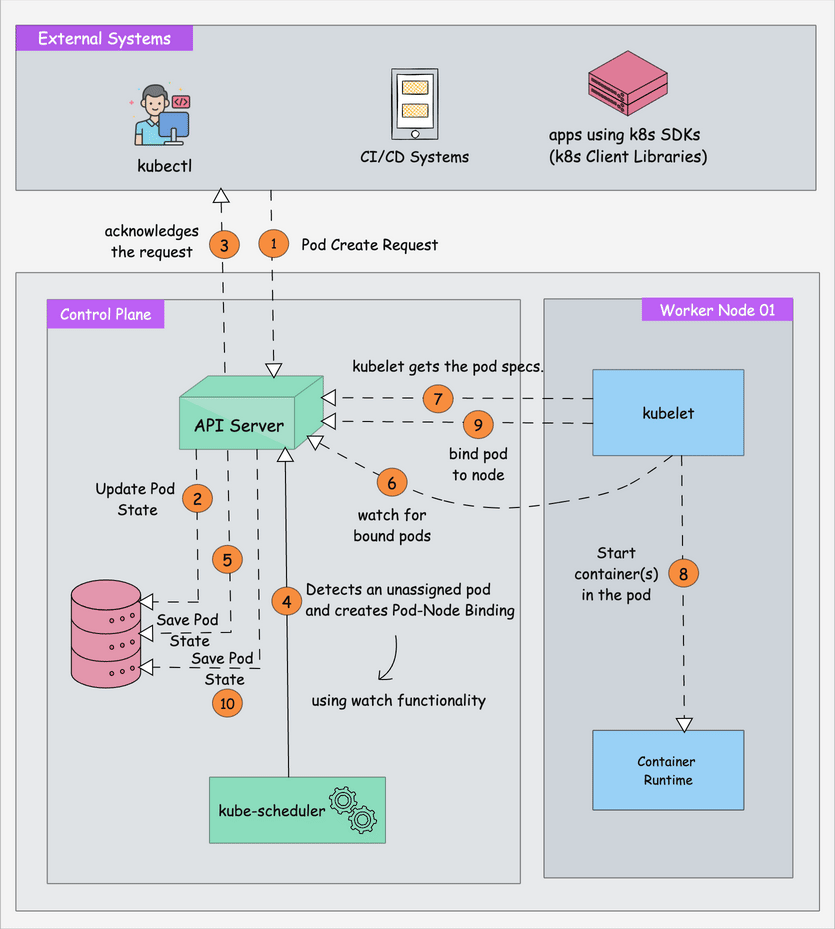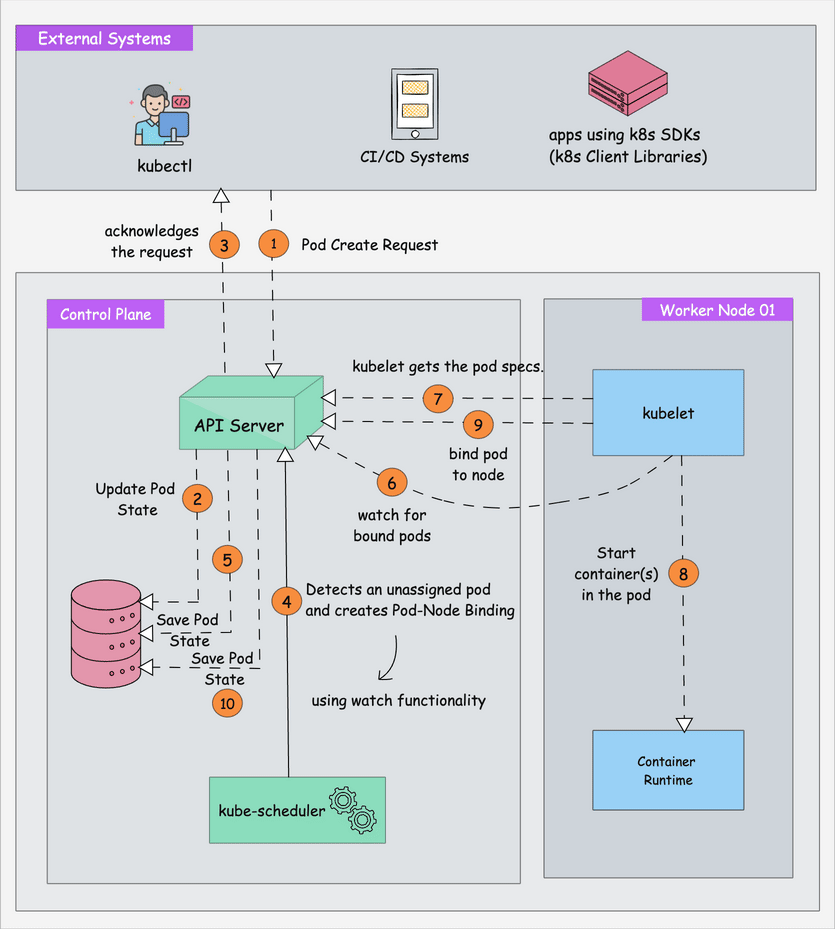
It is a feature in Kubernetes (stable since v1.34) that gives the scheduler real information about hardware devices in the cluster.
So if DRA is enabled, the scheduler can do hardware-aware scheduling for specialized devices that are particularly useful for AI/ML workloads.
4. Kube Controller Manager
What is a controller? Controllers are programs that run infinite control loops. Meaning it runs continuously and watches the actual and desired state of objects. If there is a difference in the actual and desired state, it ensures that the kubernetes resource/object is in the desired state.
As per the official documentation,
Let's say you want to create a deployment, you specify the desired state in the manifest YAML file (declarative approach). For example, 2 replicas, one volume mount, configmap, etc. The in-built deployment controller ensures that the deployment is in the desired state all the time. If a user updates the deployment with 5 replicas, the deployment controller recognizes it and ensures the desired state is 5 replicas.
Kube controller manager is a component that manages all the Kubernetes controllers. Kubernetes resources/objects like pods, namespaces, jobs, replicaset are managed by respective controllers.
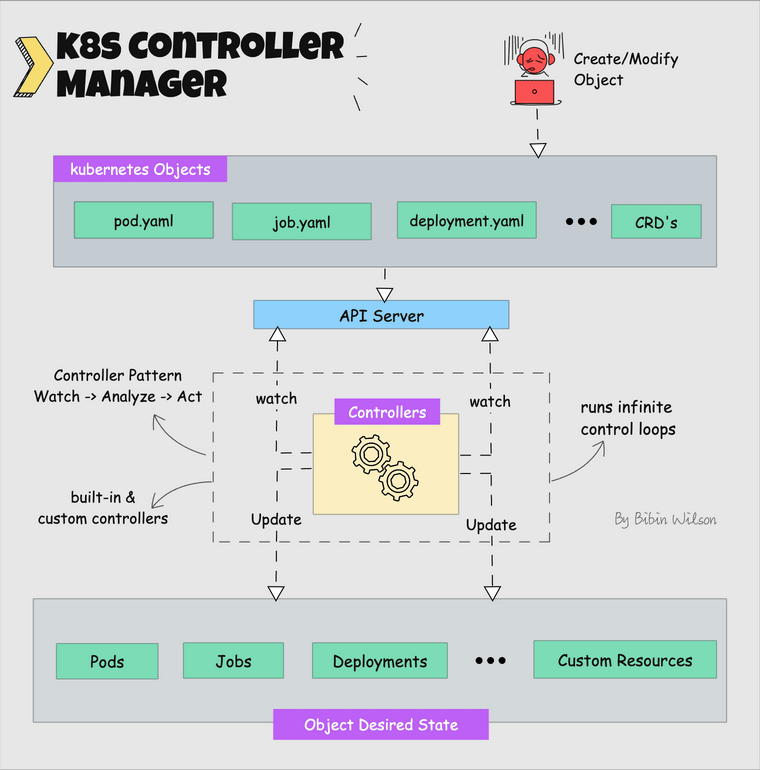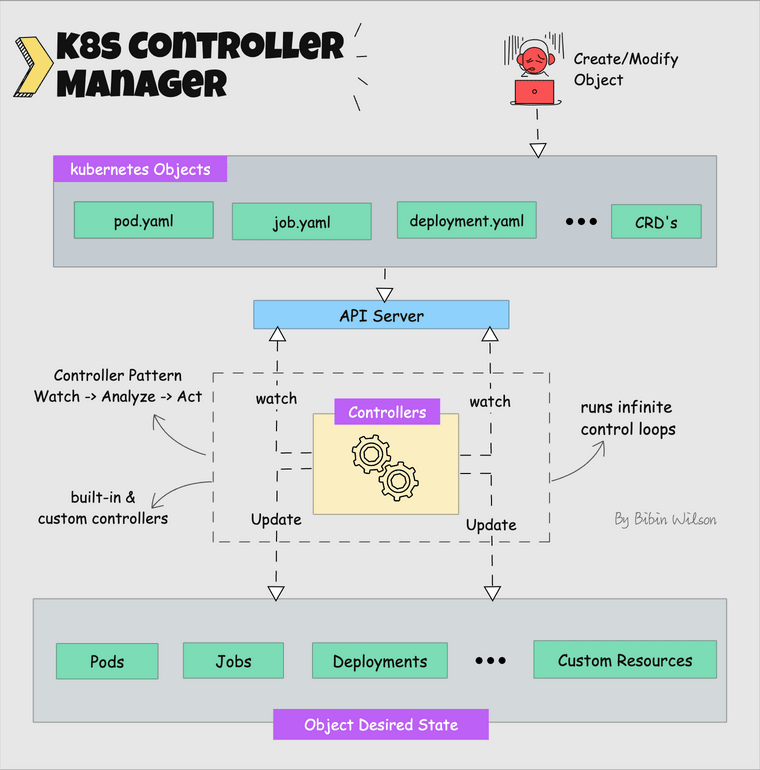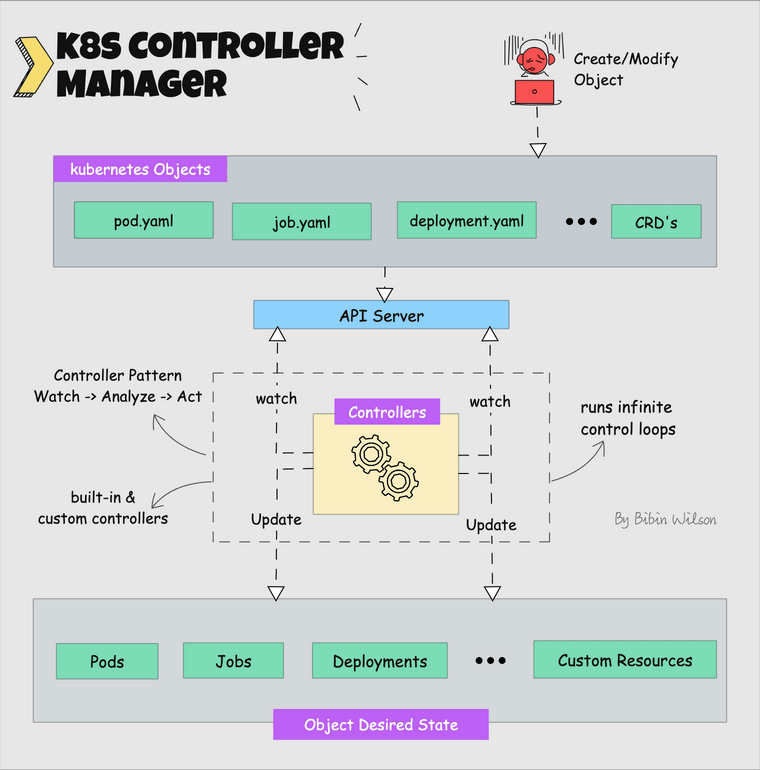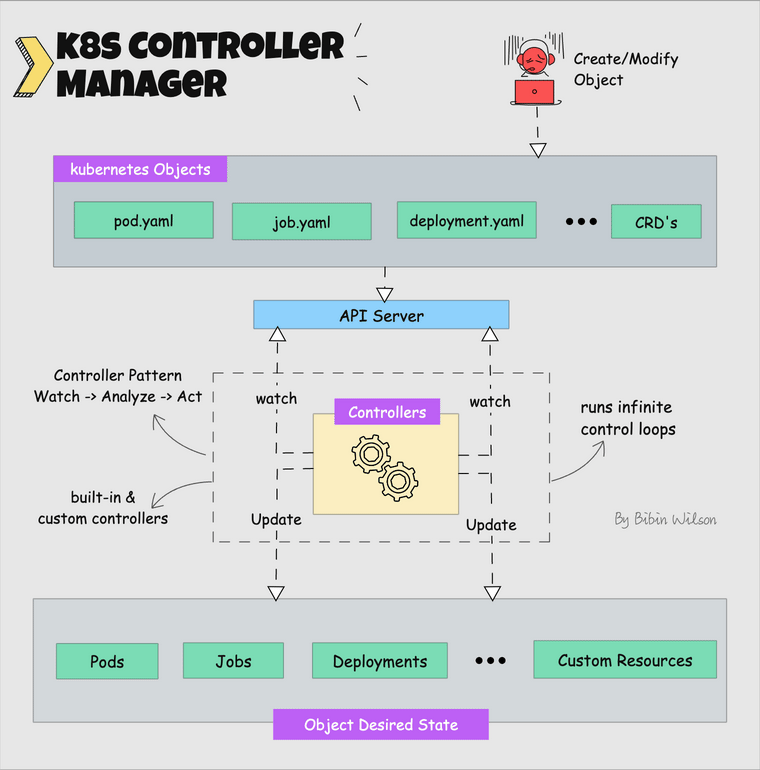
Following is the list of important built-in Kubernetes controllers.
- Deployment controller
- Replicaset controller
- DaemonSet controller
- Job Controller (Kubernetes Jobs)
- CronJob Controller
- endpoints controller
- namespace controller
- service accounts controller.
- Node controller
Here is what you should know about the Kube controller manager.
- It manages all the controllers and the controllers try to keep the cluster in the desired state.
- You can extend kubernetes with custom controllers associated with a custom resource definition.
5. Cloud Controller Manager (CCM)
When kubernetes is deployed in cloud environments, the cloud controller manager acts as a bridge between Cloud Platform APIs and the Kubernetes cluster.
This way, the core kubernetes core components can work independently and allow the cloud providers to integrate with kubernetes using Cloud Controller binaries.
Cloud Controller Manager is the bridge between Kubernetes and your cloud provider. It talks to the cloud provider's APIs to manage resources like load balancers, routes, and node metadata.
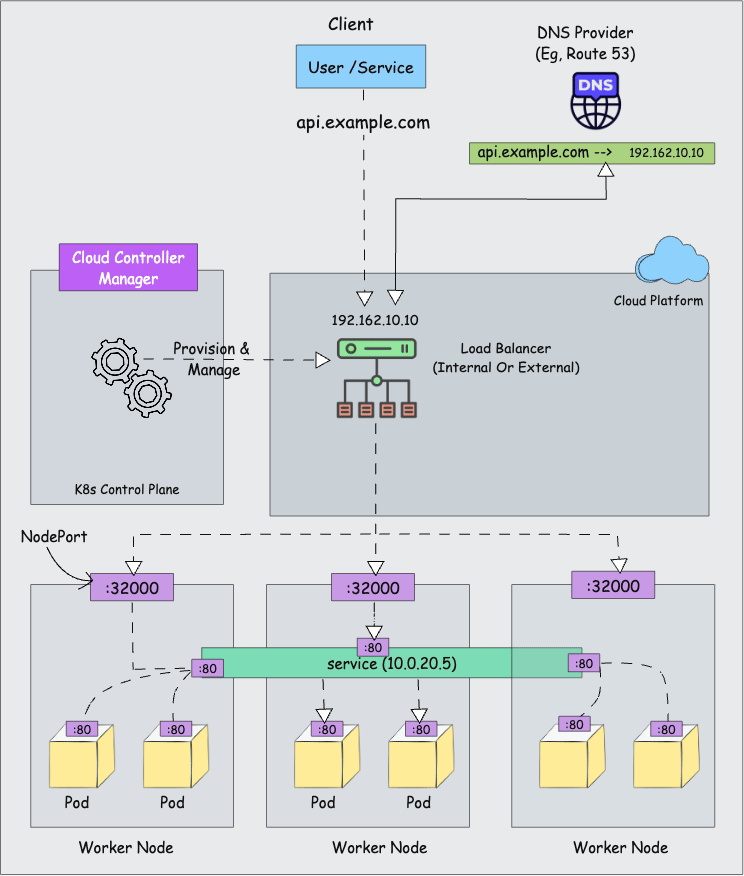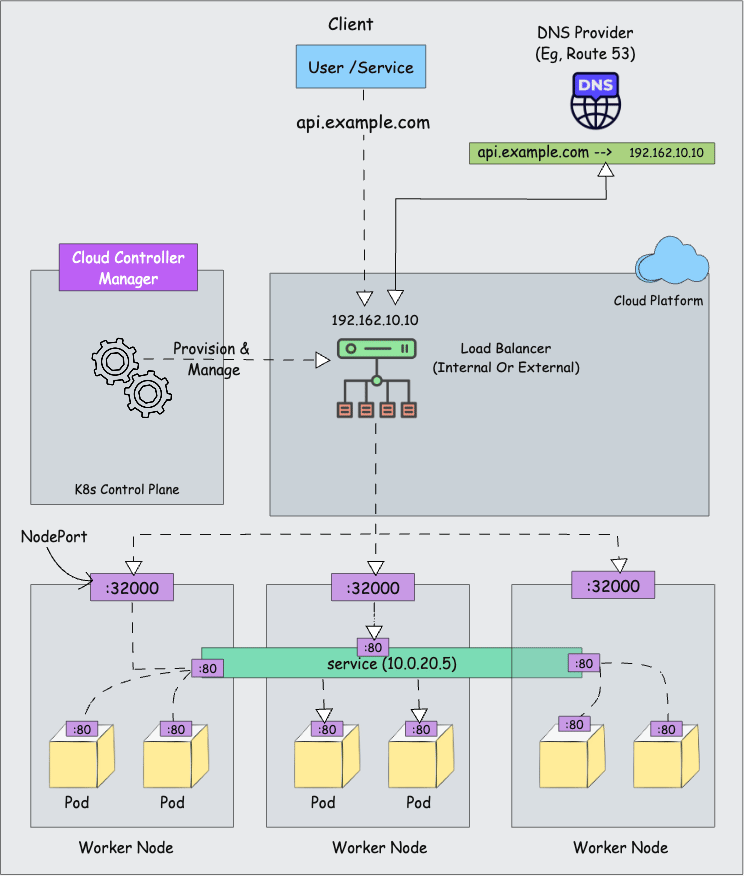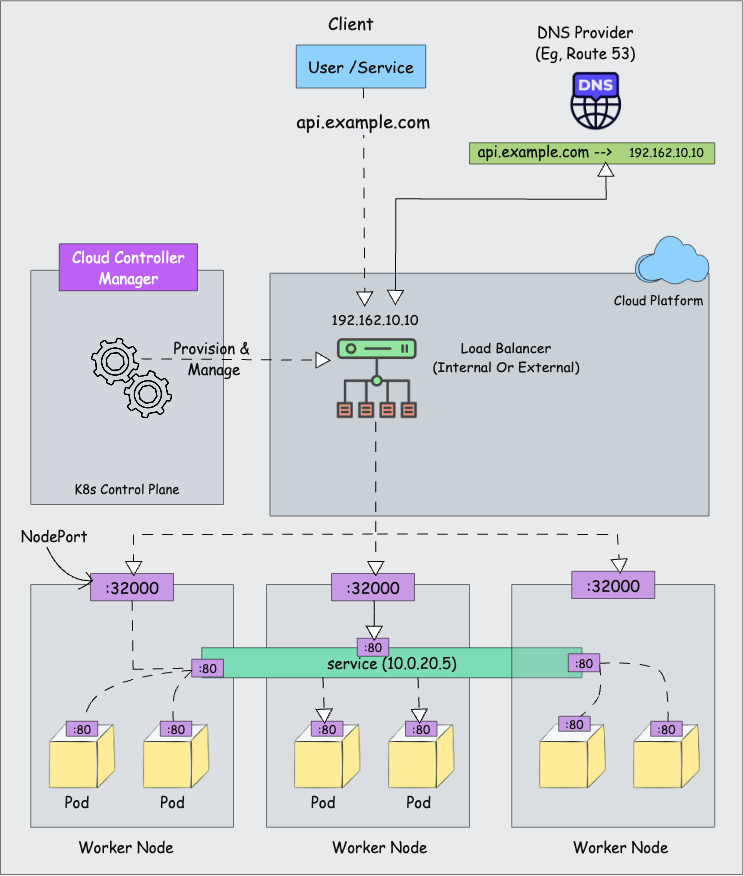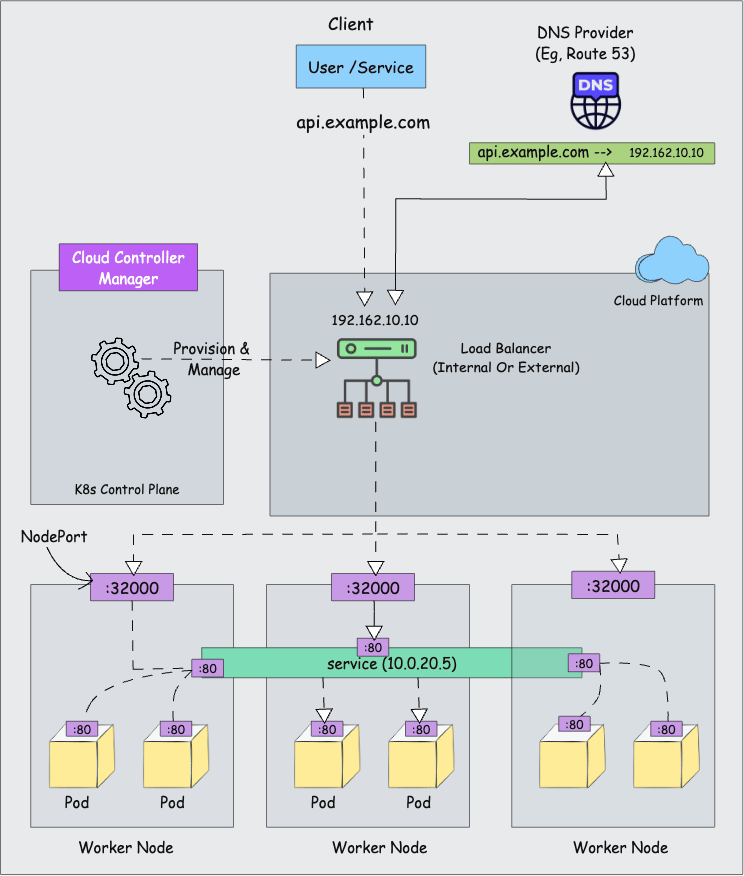
Cloud Controller Manager contains a set of cloud platform-specific controllers that ensure the desired state of cloud-specific components (nodes, Loadbalancers, storage, etc). Following are the three main controllers that are part of the cloud controller manager.
- Node controller: This controller updates node-related information by talking to the cloud provider API. For example, node labeling & annotation, getting hostname, nodes health, etc.
- Route controller: It is responsible for configuring networking routes on a cloud platform. So that pods in different nodes can talk to each other.
- Service controller: It takes care of deploying load balancers for kubernetes services, assigning IP addresses, etc.
Overall, the Cloud Controller Manager handles all cloud-specific operations by talking to the cloud provider's APIs. This keeps the core Kubernetes control plane cloud-independent.
Core Components of Kubernetes Worker Node
Now let's look at each of the worker node components.
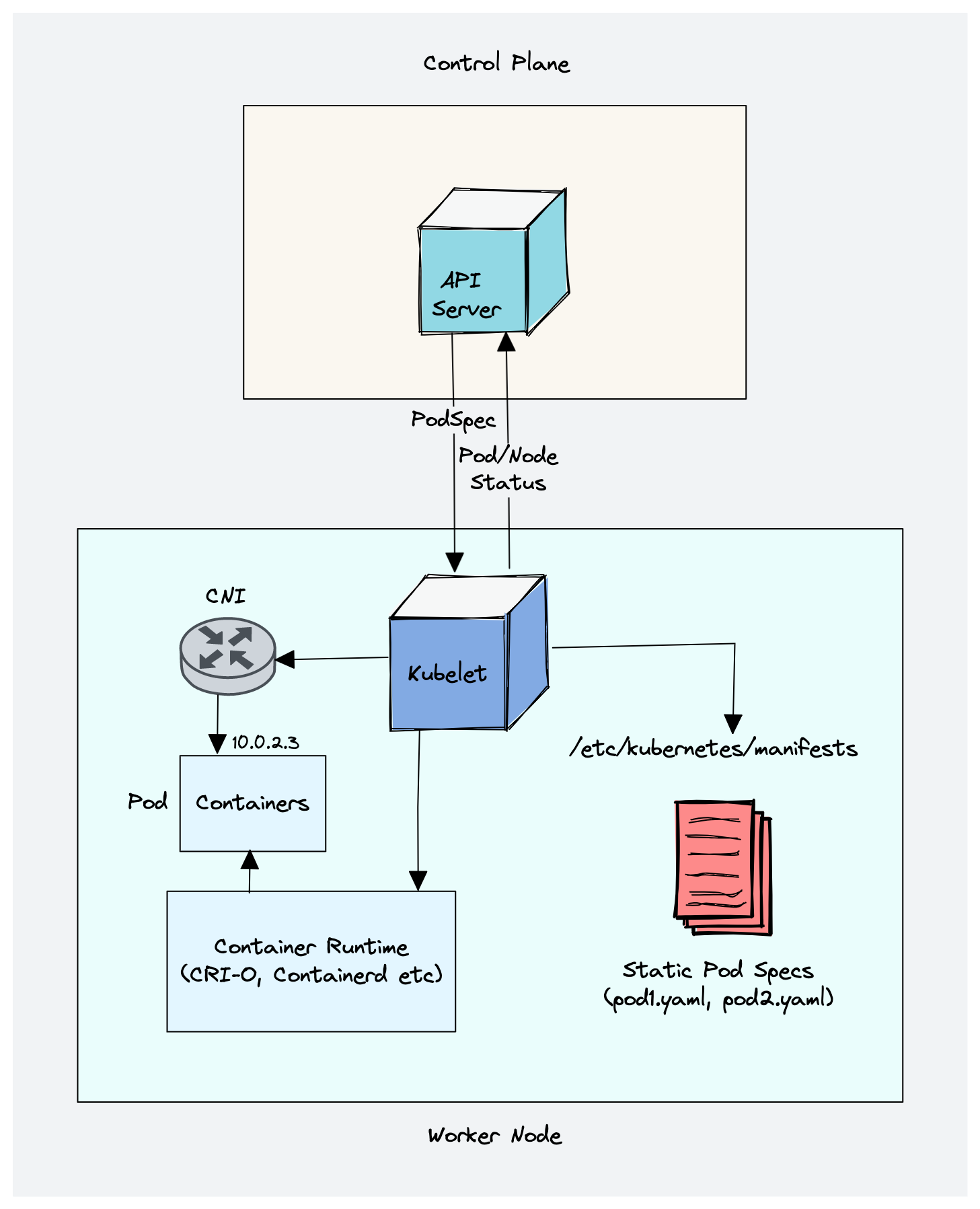
1. Kubelet
Kubelet is an agent component that runs on every node in the cluster. It does not run as a container instead runs as a daemon, managed by systemd.
It registers the node with the API server and watches for Pods scheduled to that node. When a Pod is assigned, it talks to the container runtime to create, update, or remove containers to match the desired state.
To put it simply, kubelet is responsible for the following.
- Creating, modifying, and deleting containers for the pod.
- Responsible for handling liveliness, readiness, and startup probes.
- Responsible for Mounting volumes by reading pod configuration and creating respective directories on the host for the volume mount.
- Collecting and reporting Node and pod status via calls to the API server with implementations like
cAdvisorandCRI.
Kubelet also manages Static Pods. These are defined locally on the node instead of going through the Kubernetes API. In kubeadm-based clusters, the control plane components themselves run as Static Pods during cluster bootstrapping.
Following are some of the key things about kubelet.
- Kubelet uses the CRI (container runtime interface) gRPC interface to talk to the container runtime.
- It also exposes an HTTP endpoint to stream logs and provides exec sessions for clients.
- Uses the CSI (container storage interface) gRPC to configure block volumes.
- It uses the CNI plugin configured in the cluster to allocate the pod IP address and set up any necessary network routes and firewall rules for the pod.
2. Kube proxy (Optional)
To understand kube-proxy, you need a basic understanding of Kubernetes Services and EndpointSlices.
Service in Kubernetes is a way to expose a set of pods internally or to external traffic. When you create the service object, it gets a virtual IP assigned to it. It is called clusterIP. It is only accessible within the Kubernetes cluster.
EndpointSlices store the IP addresses and ports of the Pods backing a Service. The EndpointSlice controller creates and updates them automatically as Pods come and go. This is how a Service knows which backend Pods to send traffic to.
You cannot ping the ClusterIP because it is only used for service discovery, unlike pod IPs which are pingable.
Now let's understand Kube Proxy.
Kube-proxy is a daemon that runs on every node as a daemonset. It is a proxy component that implements the Kubernetes Services concept for pods. (single DNS for a set of pods with load balancing). It primarily proxies UDP, TCP, and SCTP and does not understand HTTP.
When you expose pods using a Service (ClusterIP), Kube-proxy creates network rules to send traffic to the backend pods (endpoints) grouped under the Service object. Meaning, all the load balancing, and service discovery are handled by the Kube proxy.
So how does Kube-proxy work?
Kube proxy talks to the API server to get the details about the Service (ClusterIP) and respective pod IPs & ports. It watches Services and EndpointSlices through the API server. Whenever something changes, it updates the forwarding rules on the node.
Kube-proxy then uses any one of the following modes to create/update rules for routing traffic to pods behind a Service
- IPTables: It is the default mode. In IPTables mode, the traffic is handled by IPtable rules. This means that for each service, IPtable rules are created. These rules capture the traffic coming to the ClusterIP and then forward it to the backend pods. Also, In this mode, kube-proxy chooses the backend pod random for load balancing. Once the connection is established, the requests go to the same pod until the connection is terminated.
- NFTables: This mode It primarily addresses the performance and scalability limitations in
iptables, typically in large clusters with thousands of services.
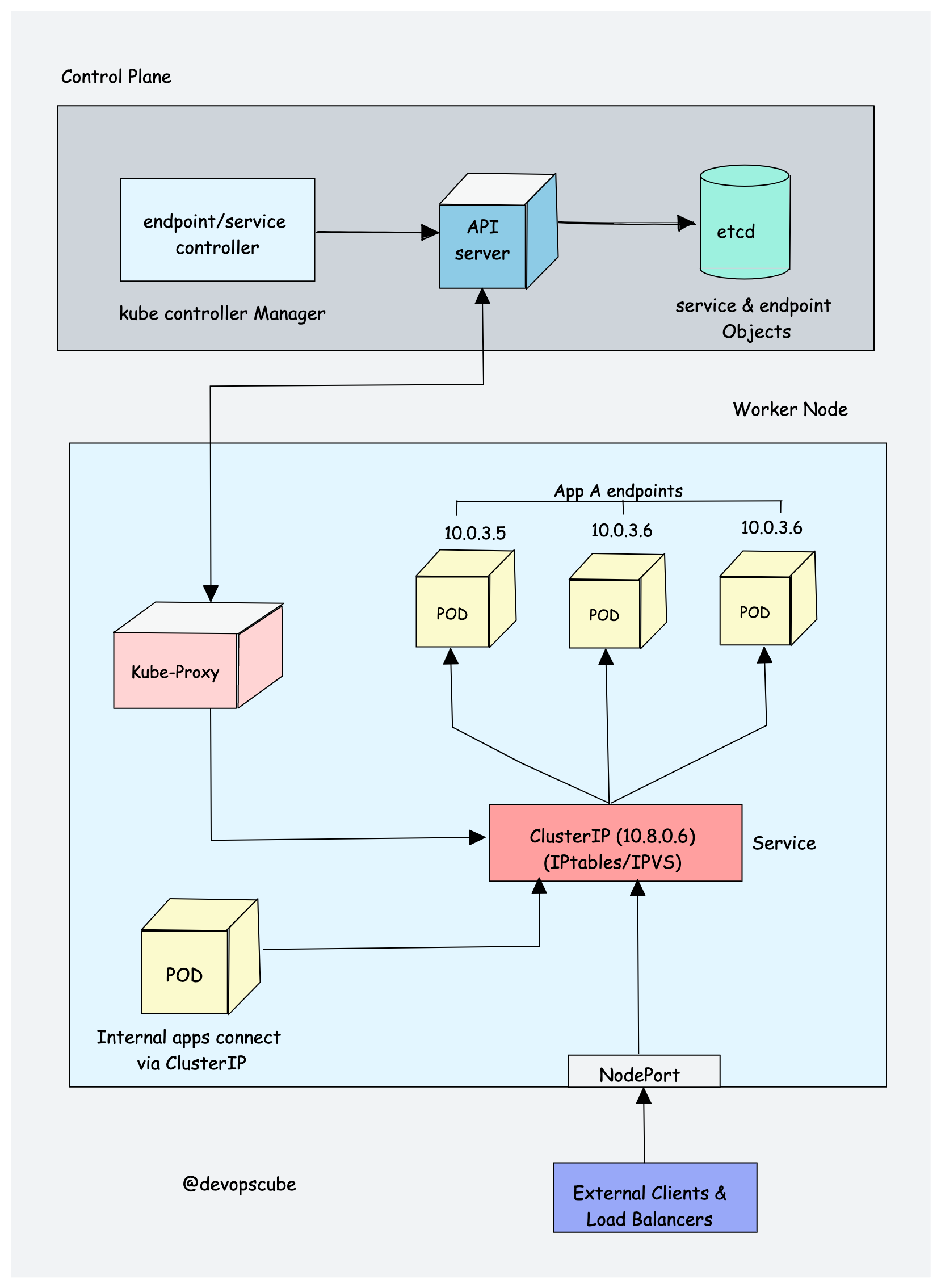
I have mentioned "optional" in the kube-proxy heading. Here is why.
Modern CNI plugins implement their own packet forwarding and load balancing logic that matches what kube-proxy does. It means kubernetes networking still works without kube-proxy running. In that case, kube-proxy can be skipped.
A classic example for this use case is Cilium (eBPF-based CNI). It uses eBPF in the Linux kernel to handle Kubernetes Service traffic (ClusterIP, NodePort, LoadBalancer) directly, without relying on the iptables/nftables rules that kube-proxy uses.
3. Container Runtime
You probably know about Java Runtime (JRE). It is the software required to run Java programs on a host. In the same way, container runtime is a software component that is required to run containers.
Container runtime runs on all the nodes in the Kubernetes cluster. It is responsible for pulling images from container registries, running containers, allocating and isolating resources for containers, and managing the entire lifecycle of a container on a host.
To understand this better, let's take a look at two key concepts:
- Container Runtime Interface (CRI): It is a set of APIs that allows Kubernetes to interact with different container runtimes. It allows different container runtimes to be used interchangeably with Kubernetes. The CRI defines the API for creating, starting, stopping, and deleting containers, as well as for managing images and container networks.
- Open Container Initiative (OCI): It is a set of standards for container formats and runtimes
Kubernetes supports CRI-compatible container runtimes such as containerd, CRI-O, and other runtimes that implement the Container Runtime Interface (CRI).
So how does Kubernetes make use of the container runtime?
As we learned in the Kubelet section, the kubelet agent is responsible for interacting with the container runtime using CRI APIs to manage the lifecycle of a container. It also gets all the container information from the container runtime and provides it to the control plane.
Kubernetes Cluster Addon Components
Apart from the core components, the kubernetes cluster needs addon components to be fully operational. Choosing an addon depends on the project requirements and use cases.
Following are some of the popular addon components that you might need on a cluster.
- CNI Plugin (Container Network Interface)
- CoreDNS (For DNS server): CoreDNS acts as a DNS server within the Kubernetes cluster. By enabling this addon, you can enable DNS-based service discovery.
- Metrics Server (For Resource Metrics): This addon helps you collect performance data and resource usage of Nodes and pods in the cluster.
- Web UI (Kubernetes Dashboard): This addon enables the Kubernetes dashboard to manage the object via web UI.
- CSI node plugins: To configure storage
Lets look at CNI plugin in detail.
CNI Plugin
First, you need to understand Container Networking Interface (CNI)
It is a plugin-based architecture with vendor-neutral specifications and libraries for creating network interfaces for Containers.
It is not specific to Kubernetes. With CNI container networking can be standardized across container orchestration tools like Kubernetes, Mesos, CloudFoundry, Podman, Docker, etc.
When it comes to container networking, companies might have different requirements such as network isolation, security, encryption, etc. As container technology advanced, many network providers created CNI-based solutions for containers with a wide range of networking capabilities. You can call it CNI-Plugins
This allows users to choose a networking solution that best fits their needs from different providers.
How does the CNI Plugin work with Kubernetes?
- The kube-controller-manager assigns a pod CIDR to each node. Every pod gets a unique IP address from this CIDR range.
- When kubelet asks the container runtime to create a Pod, the runtime calls the configured CNI plugin. The CNI plugin then creates the Pod network interface, assigns an IP address, and connects the Pod to the cluster network.
- The CNI plugin also handles networking between pods, whether they are on the same node or different nodes, typically using an overlay network.
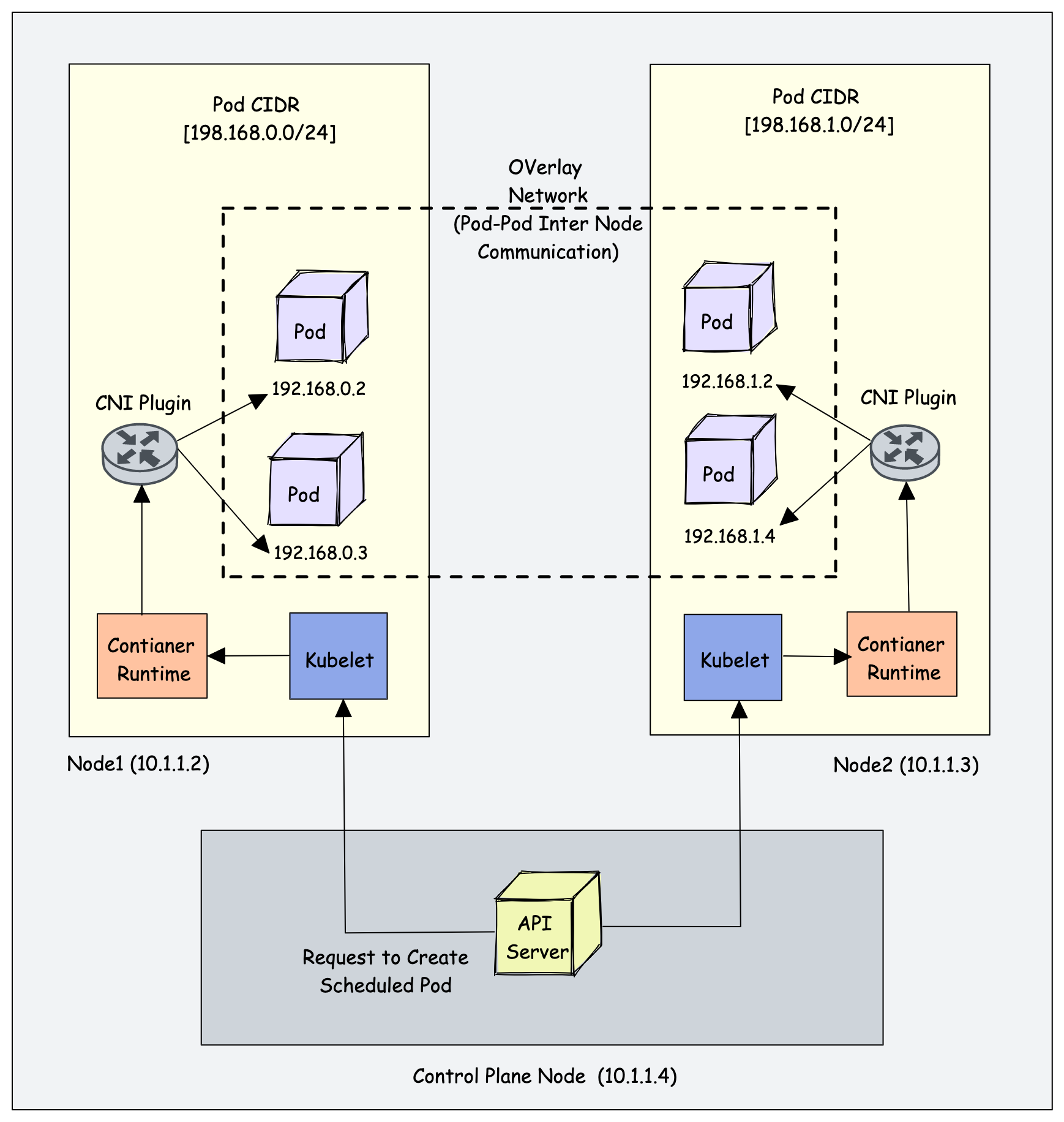
Following are high-level functionalities provided by CNI plugins.
- Pod Networking
- Pod network security & isolation using Network Policies to control the traffic flow between pods and between namespaces.
Some popular CNI plugins include:
- Calico
- Flannel
- Cilium (Uses eBPF)
- Amazon VPC CNI (For AWS VPC)
- Azure CNI (For Azure Virtual network)Kubernetes networking is a big topic and it differs based on the hosting platforms.
Kubernetes Architecture FAQs
What is the main purpose of the Kubernetes control plane?
The control plane is responsible for maintaining the desired state of the cluster and the applications running on it. It consists of components such as the API server, etcd, Scheduler, and controller manager.
What is the purpose of the worker nodes in a Kubernetes cluster?
Worker nodes are the servers (either bare-metal or virtual) that run the container in the cluster. They are managed by the control plane and receive instructions from it on how to run the containers that are part of pods.
How is communication between the control plane and worker nodes secured in Kubernetes?
Communication between the control plane and worker nodes is secured using PKI certificates and communication between different components happens over TLS. This way, only trusted components can communicate with each other.
What is the purpose of the etcd key-value store in Kubernetes?
Etcd primarily stores the kubernetes objects, cluster information, node information, and configuration data of the cluster, such as the desired state of the applications running on the cluster.
What happens to Kubernetes applications if the etcd goes down?
While the running applications will not be affected if etcd experiences an outage. It will not be possible to create or update any objects without a functioning etcd
Is kube-proxy still required?
No. While it remains part of the core, most high-performance clusters now use eBPF (like Cilium) to handle networking more efficiently.
What is L4 and L7 routing in Kubernetes?
Kubernetes Service object uses IP and Port for the traffic routing that is knows as L4 routing and Gateway API uses HTTP details like path, host, etc so is the L7 routing.
Conclusion
Understanding Kubernetes architecture helps you with day-to-day Kubernetes implementation and operations.
When implementing a production-level cluster setup, having the right knowledge of Kubernetes components will help you run and troubleshoot applications.
Also, kubernetes is no longer just a "container orchestration" tool. It is the distributed operating system for the AI era. It is becoming the top platform choice for AI/MLOps workloads as its architecture supports features required for AI/MLOps workflows.
In 2026, the architecture has evolved with features like in-place scaling, GPU-centric scheduling, and eBPF-powered networking and more.
Over to you!
Hope this guide helps you in understanding the core Kubernetes better. If you have any doubts or suggestions, do drop a comment below.