

This blog covers the fundamental Jenkins architecture and its related components. If you are a beginner in Jenkins, it will help you understand how Jenkins components work together and the key configurations involved.
What is Jenkins?
Jenkins is an easy-to-use open-source java-based CI/CD tool. It has been around for some time, and several organizations use it for their CI/CD needs.
Jenkins has huge community support and an ocean of plugins that can integrate with many open-source and enterprise tools to make your life so easy.
Despite the growing popularity of CI/CD tools like GitLab CI and GitHub Actions, which are increasingly being adopted by organizations for their CI/CD needs, Jenkins remains widely used in many organizations.
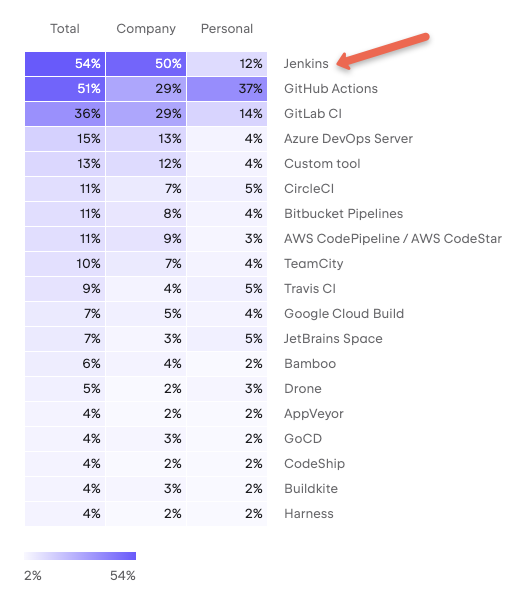
As per the Developer Ecosystem Report, 54% of the developers use Jenkins for CI/CD.
Jenkins is commonly used for the following.
- Continuous Integration for application and infrastructure code.
- Continuous delivery pipelines to deploy the application to different environments using Jenkins pipeline as code.
- Infrastructure component deployment and management using IaC Tools..
- Run batch operations using Jenkins jobs.
- Run ad-hoc operations like backups, cleanups, remote script execution, event triggers, etc.
- Jenkins Architecture
The following diagram shows the overall architecture of Jenkins and the connectivity workflow..
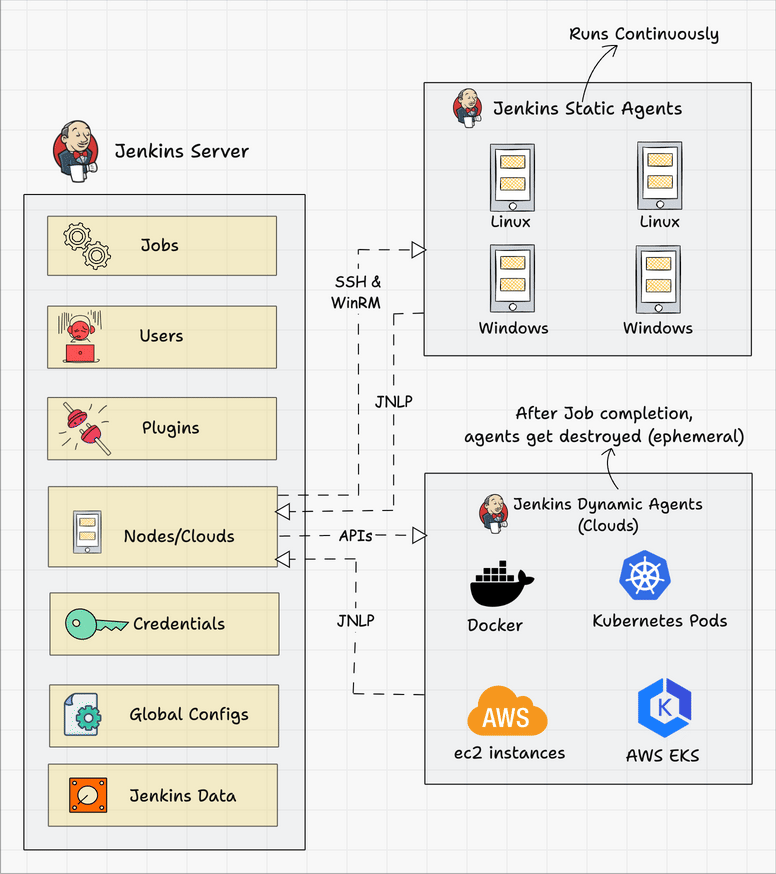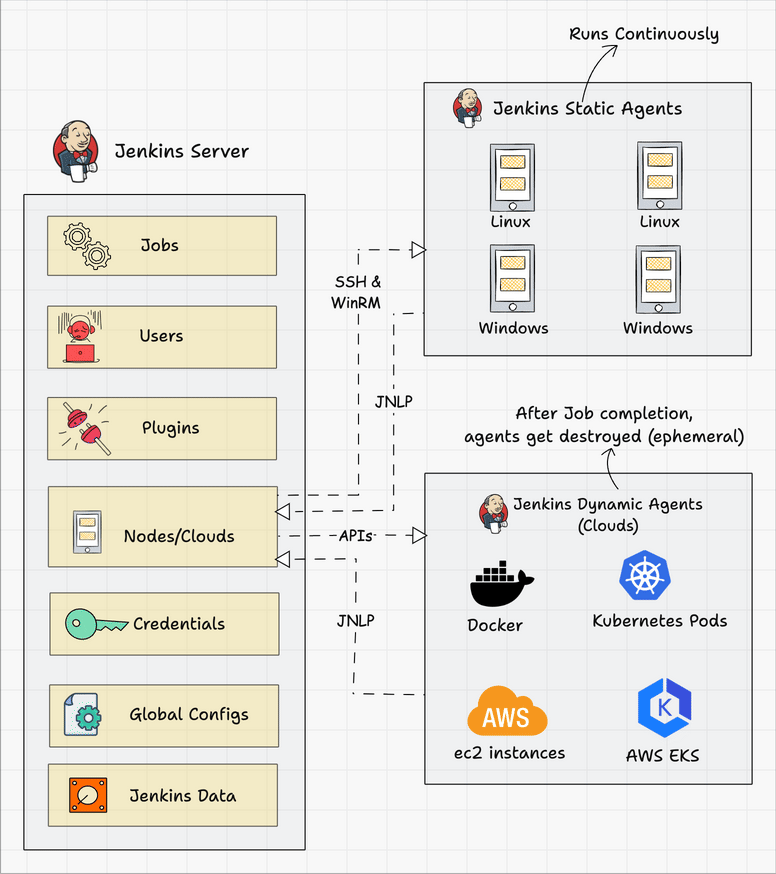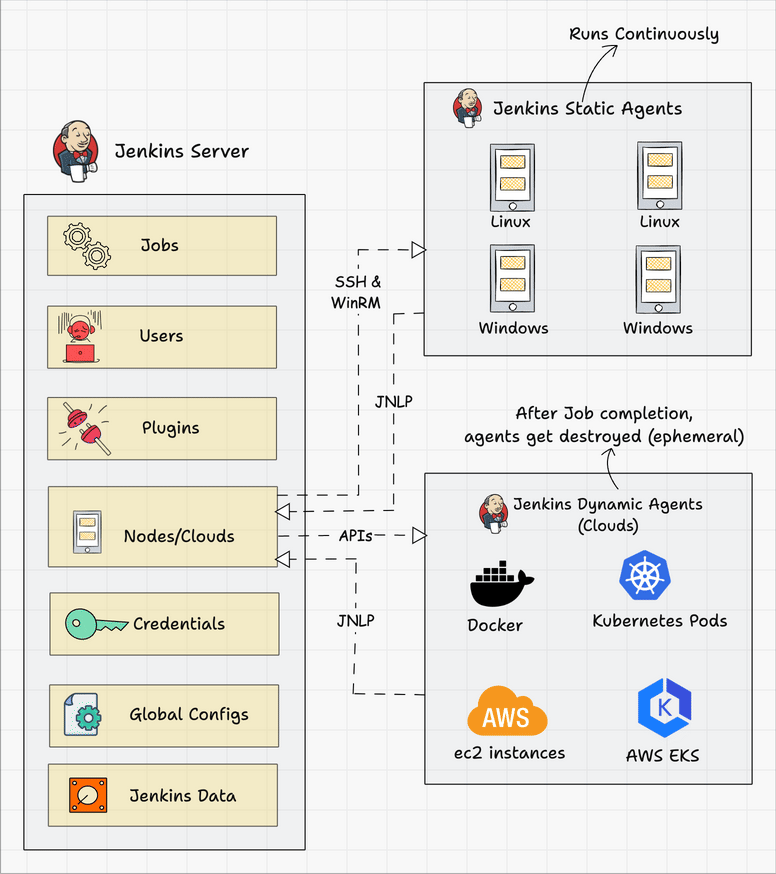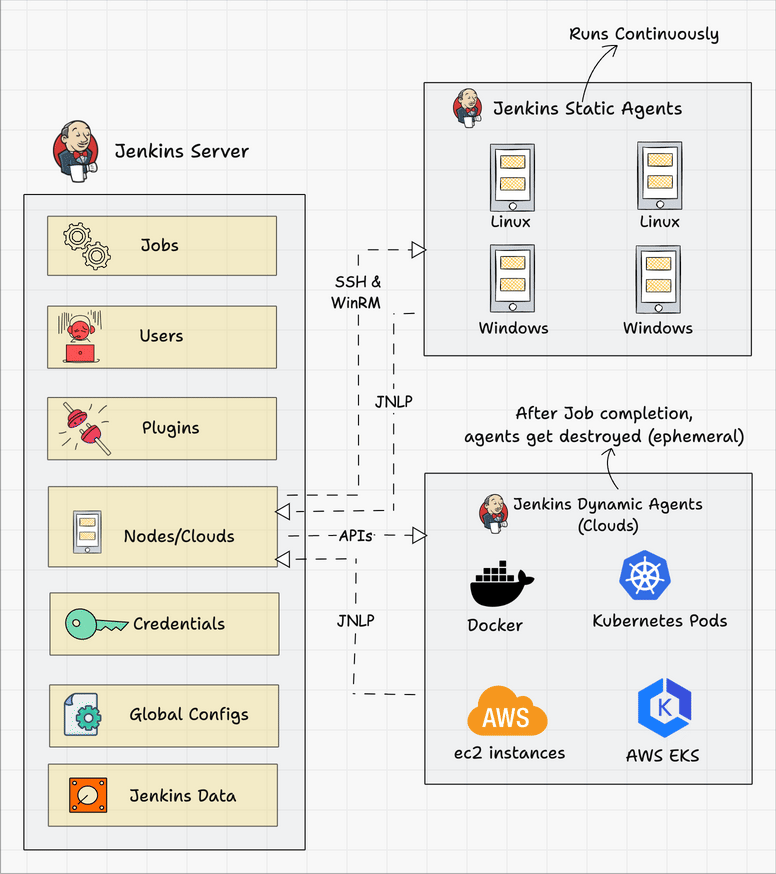
Following are the key components in Jenkins
- Jenkins Master Node
- Jenkins Agent Nodes/Clouds
- Jenkins Web Interface
Let's look at each component in detail.
Jenkins Server (Formerly Master)
Jenkins's server or master node holds all key configurations. Jenkins master server is like a control server that orchestrates all the workflow defined in the pipelines. For example, scheduling a job, monitoring the jobs, etc.
Let's have a look at the key Jenkins master components.
Jenkins Jobs
A job is a collection of steps that you can use to build your source code, test your code, run a shell script, run an Ansible role in a remote host or execute a terraform play, etc. We normally call it a Jenkins pipeline.
If you translate the above steps to a Jenkins pipeline job, it looks like the following.
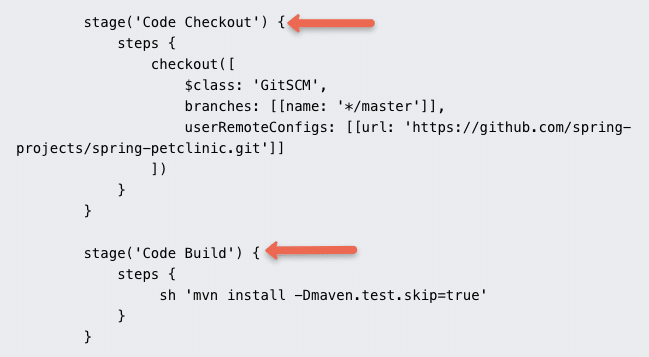
There are multiple job types available to support your workflow for continuous integration & continuous delivery.
Jenkins Plugins
Plugins are official and community-developed modules that you can install on your Jenkins server. It helps you with more functionalities that are not natively available in Jenkins.
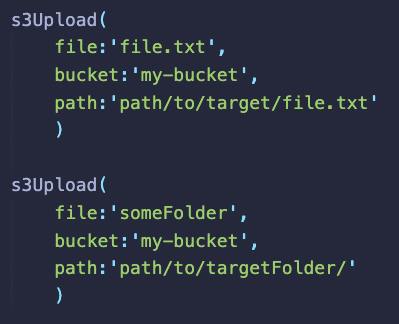
For example, if you want to upload a file to s3 bucket from Jenkins, you can install an AWS Jenkins plugin and use the abstracted plugin functionalities to upload the file rather than writing your own logic in AWS CLI. The plugin takes care of error and exception handling.
Here is an example, of s3 file upload functionality provided by the AWS Steps plugin
You can install/upgrade all the available plugins from the Jenkins dashbaord itselft. For corporate network, you will have to setup a proxy details to connect to the plugin repository.
You can also download the plugin file and install it by copying it to the plugins directory under /var/lib/jenkins folder.
You can also develop your custom plugins. Check out all plugins from the Jenkins Plugin Index
Jenkins Global Security
Jenkins has the following type of primary authentication methods.
- Jenkins's own user database:- Set of users maintained by Jenkins's own database. When we say database, its all flat config files (XML files).
- LDAP Integration:- Jenkins authentication using corporate LDAP configuration.
- SAML Single Sign On(SSO): Support single signon using providers like Okta, AzureAD, Auth0 etc..
With Jenkins matric-based security you can further assign roles to users on what permission they will have on Jenkins.
Jenkins Credentials
When you set up Jenkins pipelines, there are scenarios where it needs to connect to a cloud account, a server, a database, or an API endpoint using secrets.
In Jenkins, you can save different types of secrets as a credential.
- Secret text
- Username & password
- SSH keys
All credentials are encrypted (AES) by Jenkins. The secrets are stored in $JENKINS_HOME/secrets/ directory. It is very important to secure this directory and exclude it from Jenkins backups.
Jenkins Nodes/Clouds
You can configure multiple agent nodes (Linux/Windows) or clouds (docker, kubernetes) for executing Jenkins jobs. We will learn more about it in the agent section.
Jenkins Global Settings (Configure System)
Under Jenkins global configuration, you have all the configurations of installed plugins and native Jenkins global configurations.
Also, you can configure global environment variables under this section. For example, you can store the tools (Nexus, Sonarqube, etc) URLs as global environment variables and use them in the pipeline. This way it is easier to make URL changes that get reflected in all the Jenkins jobs.
Jenkins Logs
Provides logging information on all Jenkins server actions including job logs, plugin logs, webhook logs, etc.
Jenkins Agent
Jenkins agents are the worker nodes that actually execute all the steps mentioned in a Job. When you create a Jenkins job, you have to assign an agent to it. Every agent has a label as a unique identifier.
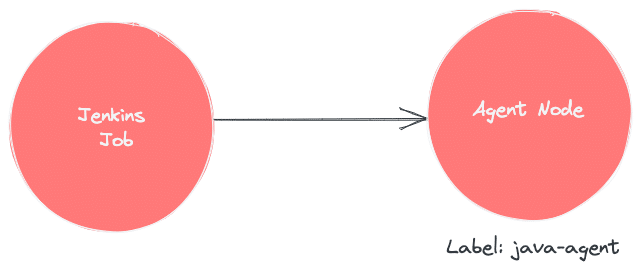
When you trigger a Jenkins job from the master, the actual execution happens on the agent node that is configured in the job.
You can have any number of Jenkins agents attached to a master with a combination of Windows, Linux servers, and even containers as build agents.
Also, you can restrict jobs to run on specific agents, depending on the use case. For example, if you have an agent with java 8 configurations, you can assign this agent for jobs that require Java 8 environment.
There is no single standard for using the agents. You can set up a workflow and strategy based on your project needs.
Jenkins server-agent Connectivity
You can connect a Jenkins master and agent in two ways
- Using the SSH method: Uses the ssh protocol to connect to the agent. The connection gets initiated from the Jenkins master. Ther should be connectivity over port 22 between master and agent.
- Using the JNLP method: Uses java JNLP protocol (Java Network Launch Protocol). In this method, a java agent gets initiated from the agent with Jenkins master details. For this, the master nodes firewall should allow connectivity on specified JNLP port. Typically the port assigned will be
50000. This value is configurable.
There are two types of Jenkins agents
- Agent Nodes: These are servers (Windows/Linux) that will be configured as static agents. These agents will be up and running all the time and stay connected to the Jenkins server. Organizations use custom scripts to shut down and restart the agents when is not used. Typically during nights & weekends.
- Agent Clouds: Jenkins Cloud agent is a concept of having dynamic agents. Means, whenever you trigger a job, a agent gets deployed as a VM/container on demand and gets deleted once the job is completed. This method saves money in terms of infra cost when you have a huge Jenkins ecosystem and continuous builds.
The following image shows a high-level view of different types of agents and connectivity types.
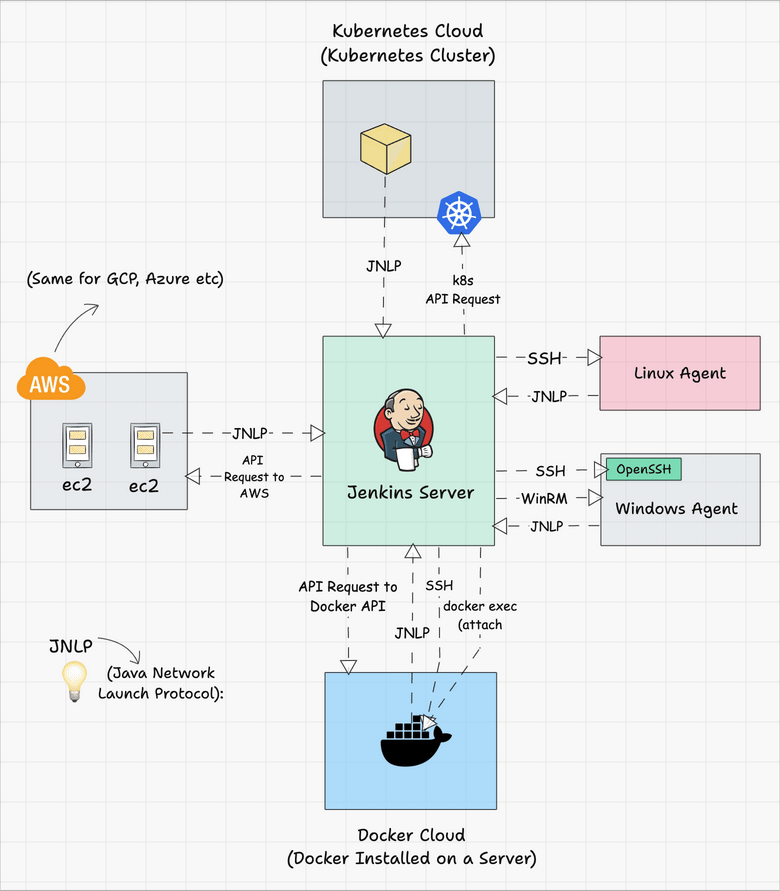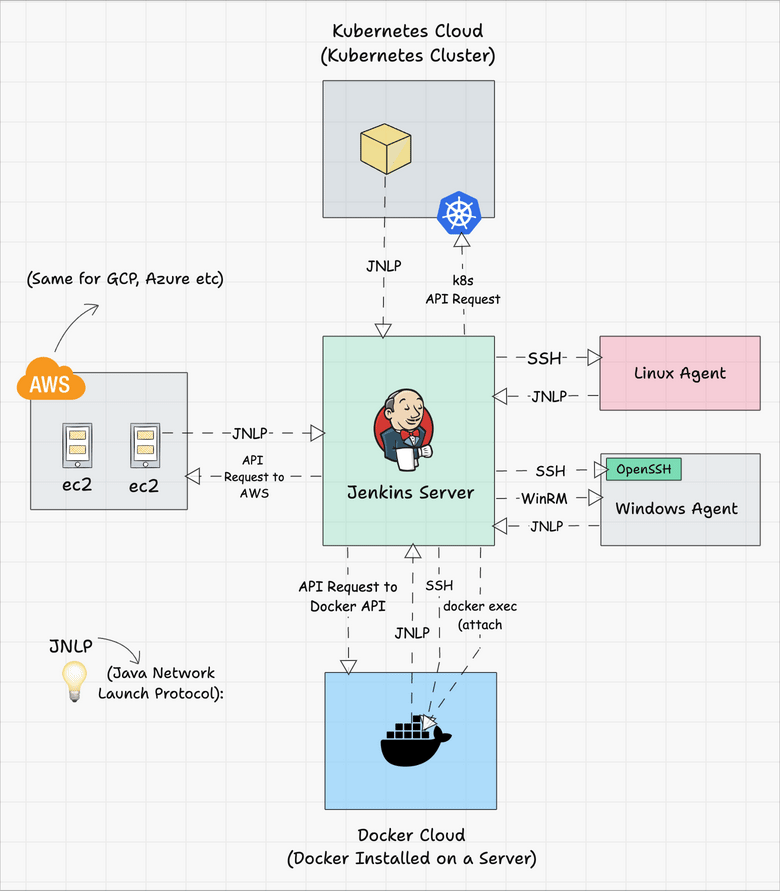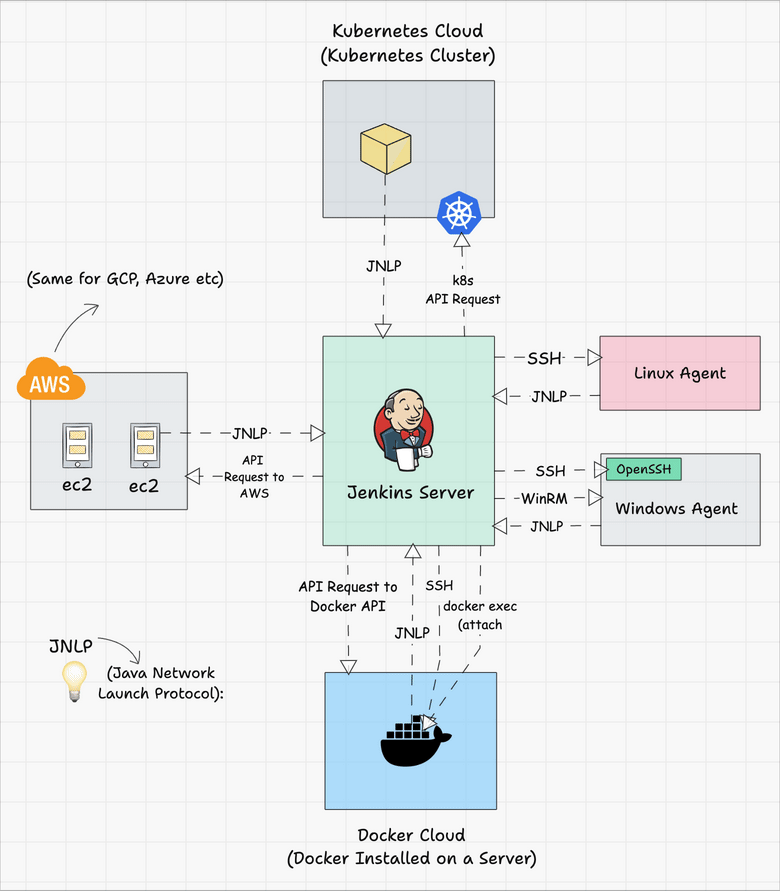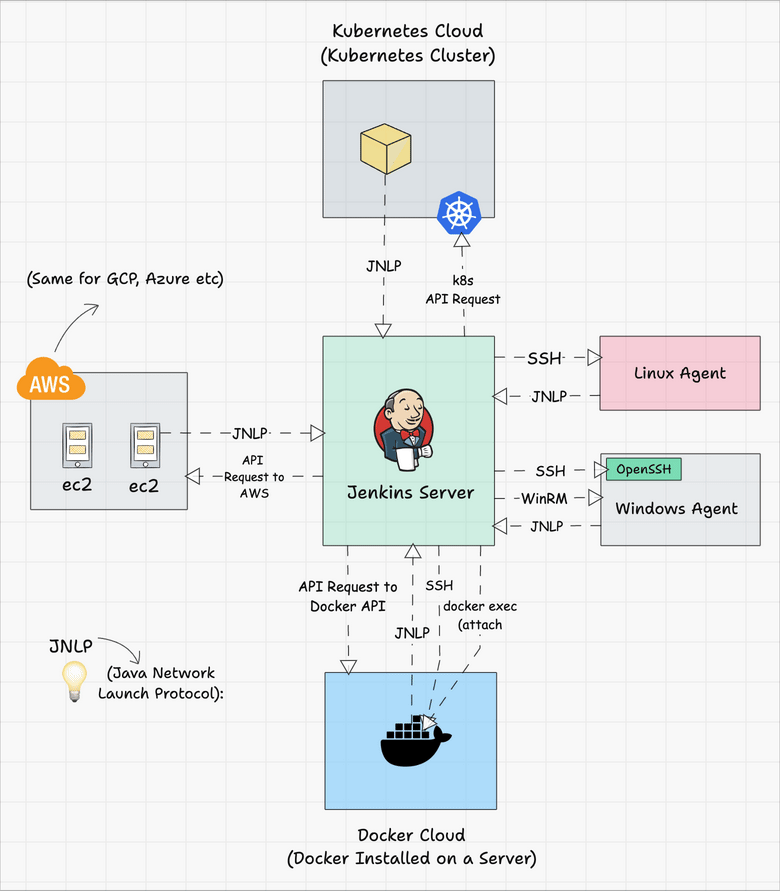
You can refer to the following tutorials to understand more about Jenkins clouds.
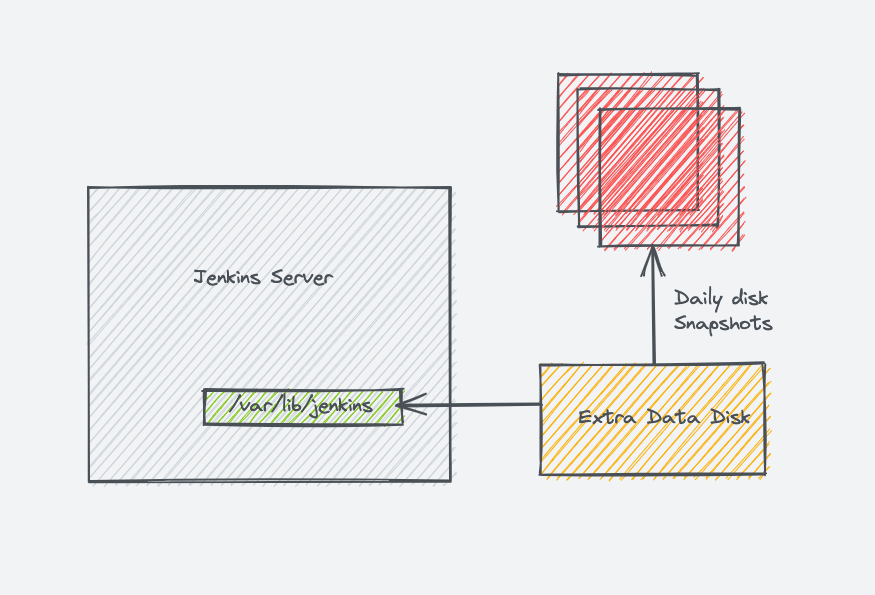
Jenkins Data
All the Jenkins data gets stored in the following folder location.
Data includes all jobs config files, plugins configs, secrets, node information, etc. It makes Jenkins migration very easy as compared to other tools.
If you take a jook at /var/lib/jenkins/ you will find most of the configurations in xml format.
It is essential to back up the Jenkins data folder every day. For some reason, if your Jenkins server data gets corrupt, you can restore the whole Jenkins with the data backup.
Ideally, when deploying Jenkins in production, a dedicated extra volume is attached to the Jenkins servers that hold all the Jenkins data.
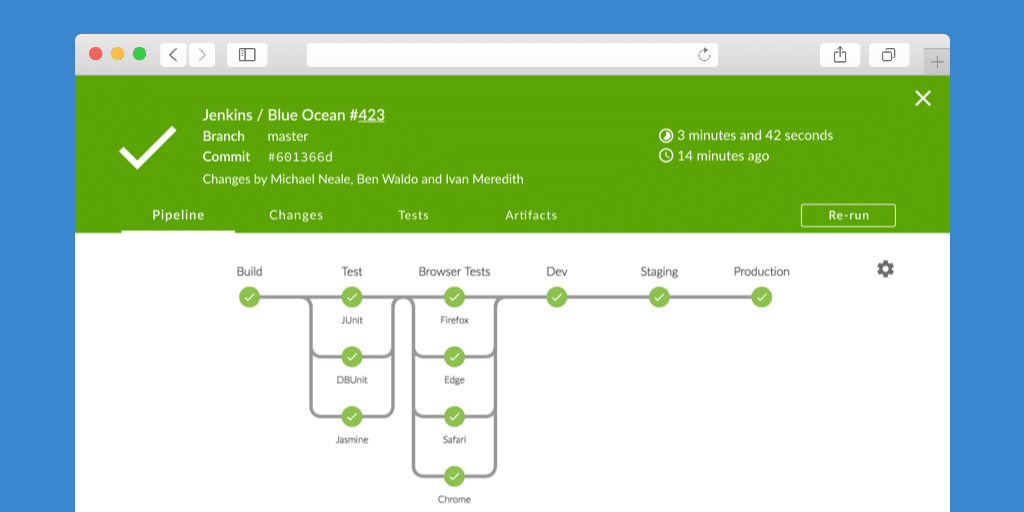
Jenkins Web Interface
Jenkins 2.0 introduced a very intuitive web interface called "Jenkins Blue Ocean". It has a good visual representation of all the pipelines.
Conclusion
In this blog, I have explained Jenkins architecture and its key components.
I personally like Jenkins for its huge community support, its extensive official and community documentation.
I have written many Jenkins tutorials from my experience. If you are pursuing a career as a DevOps engineer, this is one of the best DevOps tools to learn hands-on CI/CD.
You might be starting to learn Jenkins or have some doubts regarding its workflow.
Either way drop a comment below.
And if you want to learn about how GitLab handles CI/CD internally, check out my detailed guide on GitLab Architecture.