

This blog will discuss setting up a Highly available Jenkins using the open-source version.
Before getting into the high availability discussion, you first need to understand how Jenkins manages its data and the high-level architecture.
If you are not aware of the architecture, I highly suggest reading Jenkins architecture post.
Types of Jenkins HA Setup
There is no direct way of setting up Jenkins in High availability mode due to how Jenkins manages its data.
Jenkins manages its data in a flat-file (xml), and you can have only one instance of the master node that can read the Jenkins data.
Because of which, running multiple replicas of the Jenkins master in an active-active configuration (where all replicas are actively processing jobs) is not officially supported
For example, if you try to configure multiple master nodes with a shared volume, you will have inconsistent reads and writes that lead to unstable Jenkins.
There are two ways you can have Jenkins in HA mode.
- Jenkins active-actice/active-passive setup: Only enterprise Jenkins comes with a supported plugin to have this setup. But most organizations use open-source versions, and his option is out of scope. Also, there is an option with HAproxy, however, I think it's a bit of administrative overhead.
- Jenkins HA setup in autoscaling Group: Having Jenkins in the autoscaling group is a workaround to have a highly available Jenkins. It is not a 100% HA solution; however, for any reason if your Jenkins server crasher, another instance will come up within a short period. This will work on both VM and Kubernetes based Jenkins setup
Jenkins HA Setup With Autoscaling Group
You can call this method a poor man's solution for Jenkins HA. Because, when an instance goes down, there are a few minutes of downtime for another instance to come up (vm + java service startup time). But it works :)
This method will work on any private/public cloud platform with the option of autoscaling.
This method is similar to deploying Jenkins on Kubernetes, where if the Jenkins pod goes down, another pod will come up with the same data.
Instead of a pod, it's a VM., so the startup time takes more time than spinning up a new pod.
Let's look at the high-level architecture of the Jenkins HA setup using an autoscaling group.
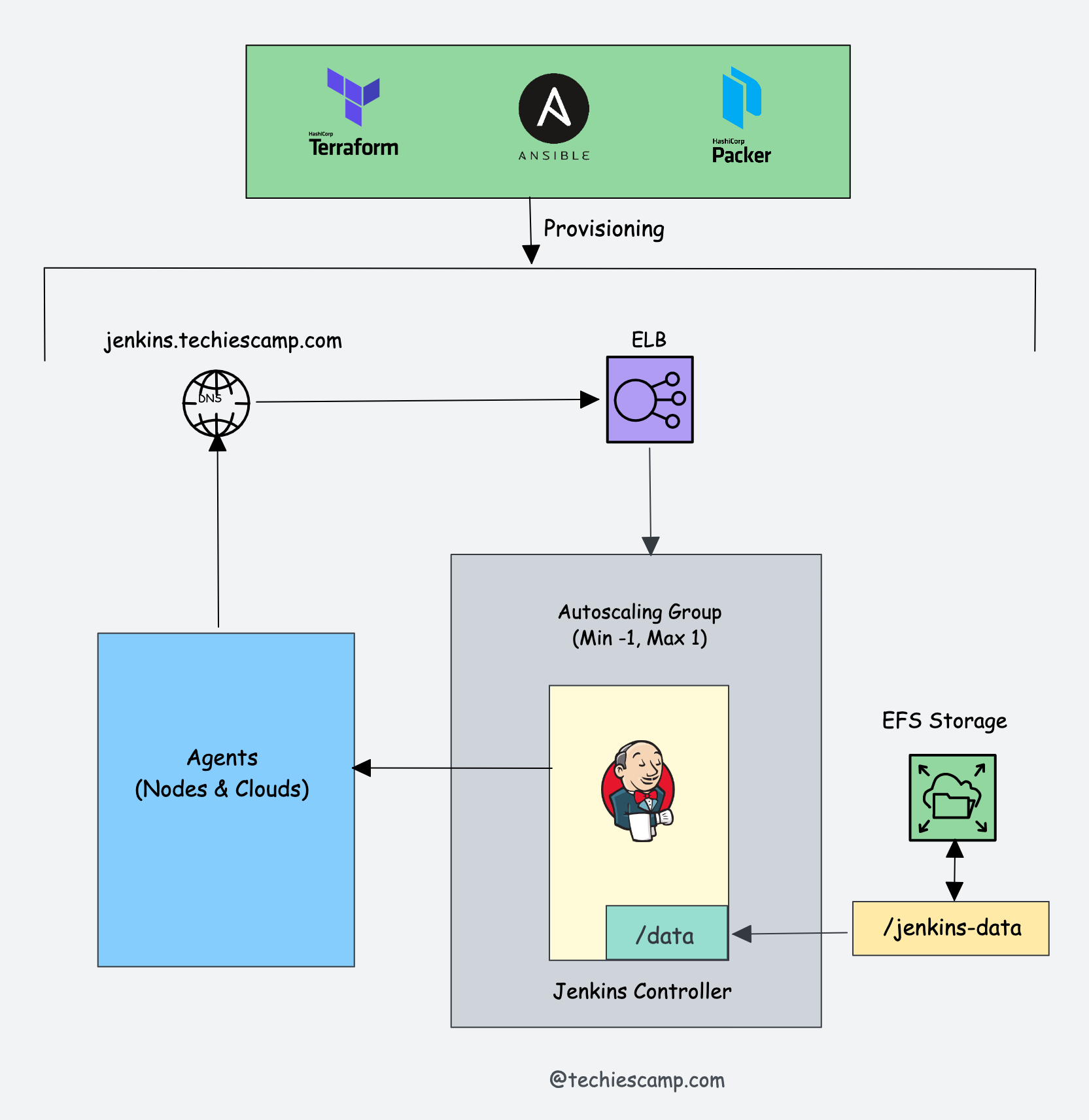
Here the concept is pretty simple.
- Jenkins is deployed in an autoscaling group with min and max one count. It ensures we have only one instance of Jenkins running all the time.
- Then, we have a dedicated external disk to hold the Jenkins data. It could be a separate volume or an NFS share. The autoscaling image startup script (AMI user data) gracefully attaches this disk when it comes up.
- If the active Jenkins instance goes down, the autoscaling policies will bring up another instance while terminative the inactive one. In this process, the data disk gets detached from the terminating instance gracefully (in AWS using lifecycle hooks) and gets attached to the new instance, preserving the previous Jenkins state and data.
- All the existing jobs will fail during downtime or continue when a new instance comes up.
This setup also makes the upgrade and patching process so easy.
HA Setup on Kubernetes
When deployed in Kubernetes, It should be deployed via StatefulSet. Also, wee need to keep the StatefulSet replica as one and the Jenkins data directory should be mounted to the a Persistent Volume to store Jenkins data (e.g., job history, plugins, configurations).
This ensures data persists even if the Jenkins master pod is rescheduled or restarted.
Horizontal Scaling For Agents
A good news is, you can scale Jenkins agents horizontally.
There are several ways to scale Jenkins agents. In this method, the agents are dynamically provisioned and terminated once the build is completed.
For example,
- Scaling Agents with Kubernetes pods
- Scaling Agents with Docker
- Scaling Agents with ec2 instances.
Jenkins HA Setup
If you want to try this setup on the AWS cloud, you can use my Documentation.
I have documented the whole setup for AWS here -> Jenkins HA Setup Using AWS Autoscaling Group
The IaC code for the setup is present in the DevOps Projects Githup Repo
https://github.com/techiescamp/devops-projectsDo try out this setup and see if it works for you.
Also, you should backup jenkins data periodically using plugins and disk snapshots. You can easily restore a working version if you have all the data backup.
If you are new to Jenkins, check out our Jenkins tutorial for beginners.
