

In this guide we will look in to Kubernetes high availability. We will also look at resileinecy and fault tolerance of each Kubernetes component.
Need for Kubernetes High Availability
Kubernetes is a distributed system and it is subject to multiple failures.
It is essential for organizations to have highly available Kubernetes for providing a good customer experience. In an event of unexpected disruption, if you don't have a cluster that continues to function despite one or more component failures, the downtime could lead to revenue loss, reputation issues etc.
By implementing HA in Kubernetes, the risk of downtime is reduced, applications and services that run on the cluster remain available and accessible to users and and the system can quickly recover from failures without human intervention.
In a high level, this can be achieved by deploying multiple replicas of control plane components with a network topology spanning across multiple availability zones or regions.
High Availability for Kubernetes Control Plane
Kubernetes control plane has the following core components.
- API server
- Kube controller manager
- Kube Scheduler
- Cloud Controller Manager (Optional)
Running a single node control plane could lead to single point of failure of all the control plane components. To have a highly available Kubernetes control plane, you should have a minimum of three quoram control plane nodes with control plane components replicated across all the three nodes.
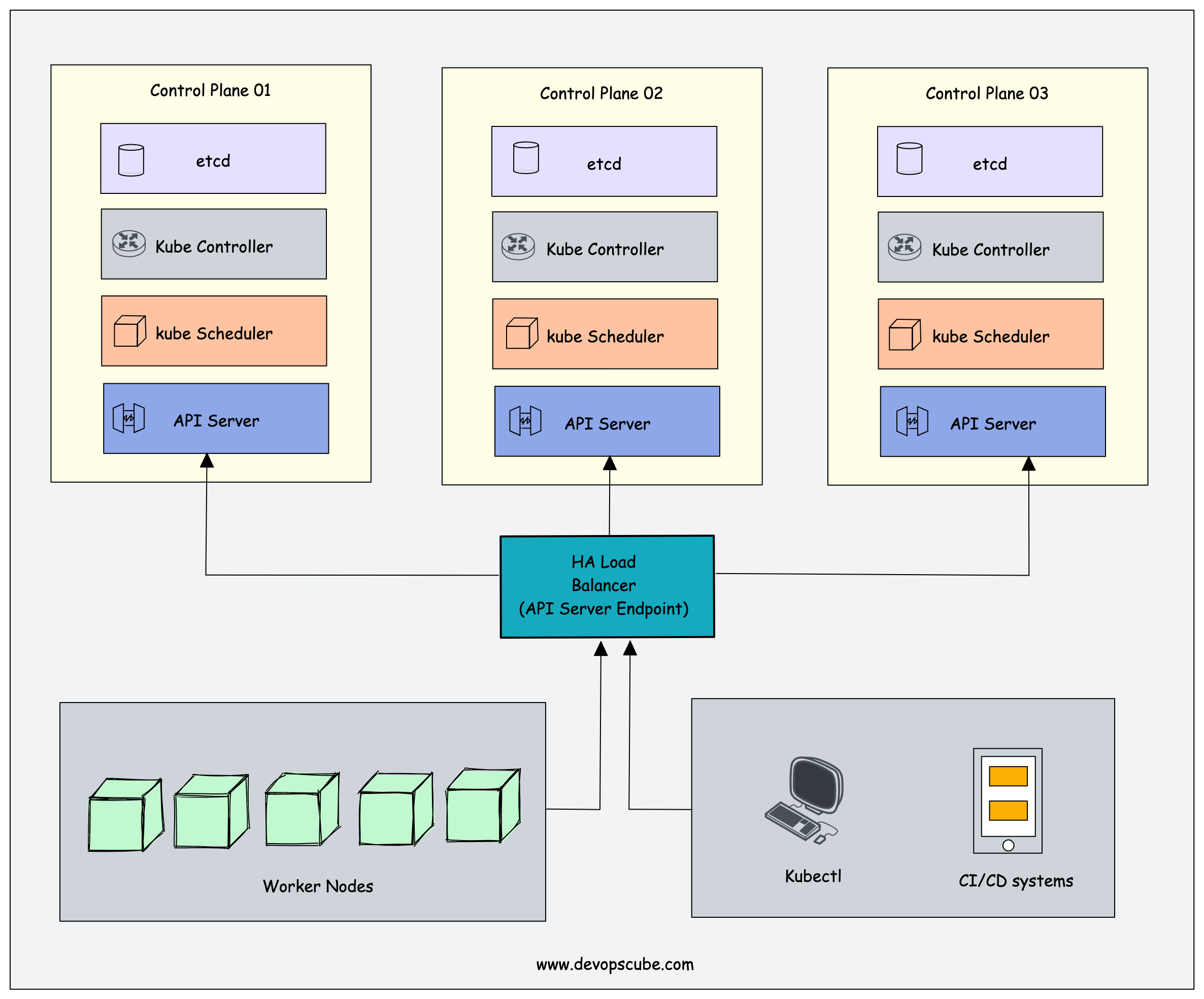
Now, its very important for you to understand the nature of each control plane component when deployed as multiple copies across nodes. Because few components use leader-election when deployed as multiple replicas.
Lets have a look at each control place components in terms of high availabiltiy.
etcd
When it comes to etcd HA architecture, there are two modes.
- Stacked etcd: etcd deployed along with control plane nodes
- External etcd cluster: Etcd cluster running dedicated nodes. This model has the advantage of well-managed backup and restore options.
To have fault tolerance you should have a minimum of three node etcd cluster. The following table shows the fault tolerance of the etcd cluster.
| Cluster Size | Majority | Failure Tolerance |
|---|---|---|
| 1 | 1 | 0 |
| 2 | 2 | 0 |
| 3 | 2 | 1 |
| 4 | 3 | 1 |
| 5 | 3 | 2 |
| 6 | 4 | 2 |
| 7 | 4 | 3 |
etcd fault tolerance
When it comes to production deployments, it is essential to backup etcd periodically
Api Server
The API server is a stateless application that primarily interacts with the etcd cluster to store and retrieve data. This means that multiple instances of the API server can be run across different control plane nodes.
To ensure that the cluster API is always available, a Load Balancer should be placed in front of the API server replicas. This Load Balancer endpoint is used by worker nodes, end-users, and external systems to interact with the cluster.
Kube Scheduler
When you run multiple instances of kube scheduler, it follows the leader-election method. This is because, schedler component is involved pod scheduling activities and only one instance can make decision at a time. So when you run multiple replicas of scheduler one instance will be elected as a leader and others will be marked as followers.
This ensures that there is always a single active scheduler, making scheduling decisions, and avoiding conflicts and inconsistencies. In the event if leader, a follower will be elected a leader and takes over all the scheduling decisions. This way you have a highly available scheduler with consistent schedling.
Kube Controller Manager
Kuber controller manager also follows the same leader-elections method. Out of many replicas, one controller manager is elected and leader and others are marked as followers. The leader controller is responsible for controlling the state of the cluster.
Cloud Controller Manager
The Cloud Controller Manager (CCM) is a Kubernetes component that runs controllers that interact with cloud-provider-specific APIs to manage resources such as load balancers, persistent volumes, and routes.
Just like the scheduler and kube-controller, the CCM also uses leader election to ensure that there is only one active replica making decisions and interacting with the cloud-provider APIs at a time.
High Availability for Worker Nodes
For worker node high availability, you need to run multiple worker nodes that is required for your applications. When there is a pod scaling activity or a node failure there should be enough capacity on other worker nodes for the pods to get scheduled.
On cloud platforms, you can scale worker nodes using autoscaling. So when there is a scaling activity or resource requirements, the worker nodes can scale to the desired capacity.
Kubernetes Cluster Availability Measurements
Assuming no planned downtime, the following table from the Google SRE book, shows the calculations on how much downtime is permitted based on different availability levels
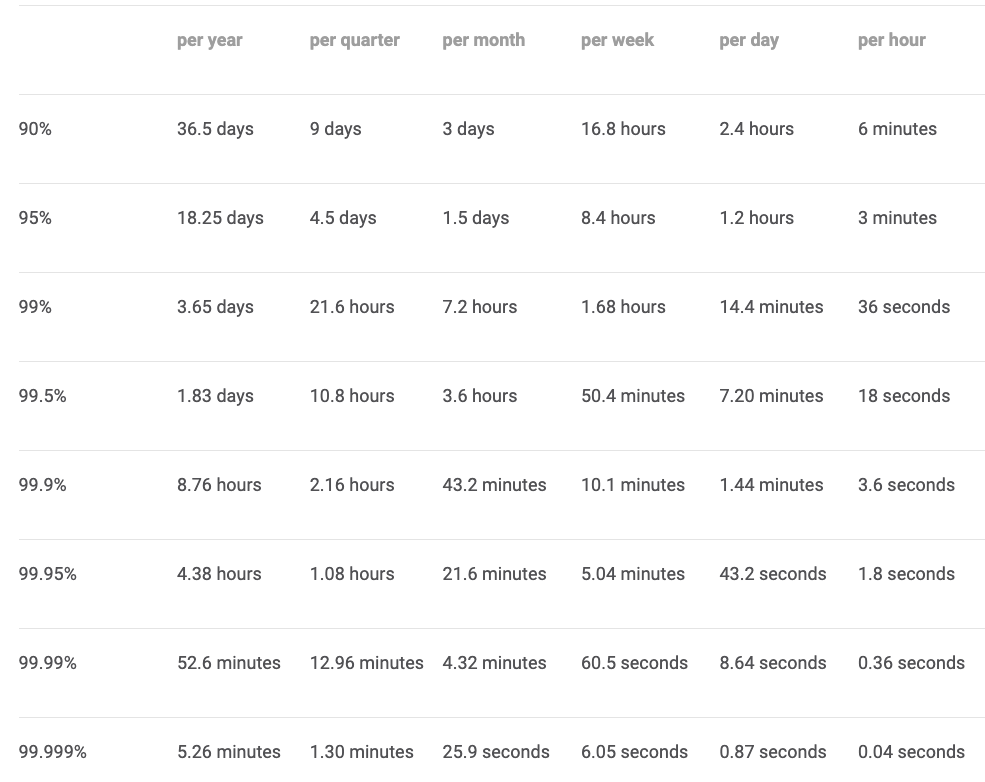
Each organization would have SLOs for cluster availability. If you are using managing services, the service provider would have SLAs aligned with the SLOs
Following are the SLAs provided
Kubernetes Availability FAQs
What Happens During Control Plane Failure?
In an even of control plane failure the exiting workloads on the worker nodes continue to server the requests. However if there a node failure, pod scheduling activity or any type of update activity will not happen
What happens if DNS service fails in a Kubernetes Cluster?
If DNS service like Core DNS fails, it can have a significant impact on the availability and functionality of the applications running in the cluster. It can disrupt service discovery, external access, load balancing, monitoring and logging, and rolling updates, leading to application failures, errors, and outages.
