

Looking to understand what containers are and how they work? Our comprehensive guide explains the basics of containerization, including definitions, benefits, and use cases.
If you are new to the world of containers, learning the fundamentals is essential. This will help you to effectively learn tools such as Docker and orchestration tools like Kubernetes.
Now let's understand what a Linux Container is.
What is a Container?
In a typical virtualized environment, one or more virtual machines run on top of a physical server using a hypervisor like Xen, Hyper-V, etc.
On the other hand, Containers run on top of the operating system's kernel. You can call it OS-level virtualization. Before getting into the underlying container concepts, you need to understand two key Linux concepts.
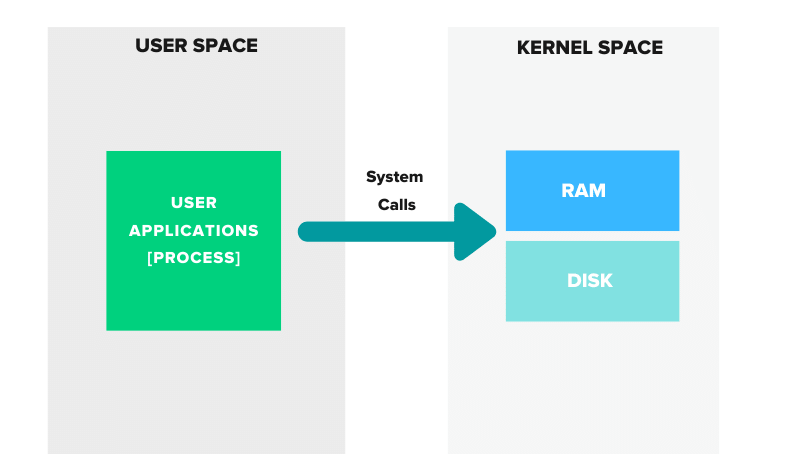
- Userspace: All the code required to run user programs (applications, process) is called userspace. When you initiate a program action, for example, to create a file, the process in the userspace makes a system call to Kernal space.
- Kernel Space: This is the heart of the operating system, where you have the kernel code, which interacts with the system hardware, storage, etc.
Container Process Isolation
When you start an application – such as an Nginx web server – you’re essentially starting a process. A process is a self-contained set of instructions with limited isolation.
But what if you could isolate the process, along with only the files and configurations necessary to run and operate it? That’s precisely what a container does.
By creating an isolated environment for the process, a container allows for greater security, consistency, and portability across different systems.
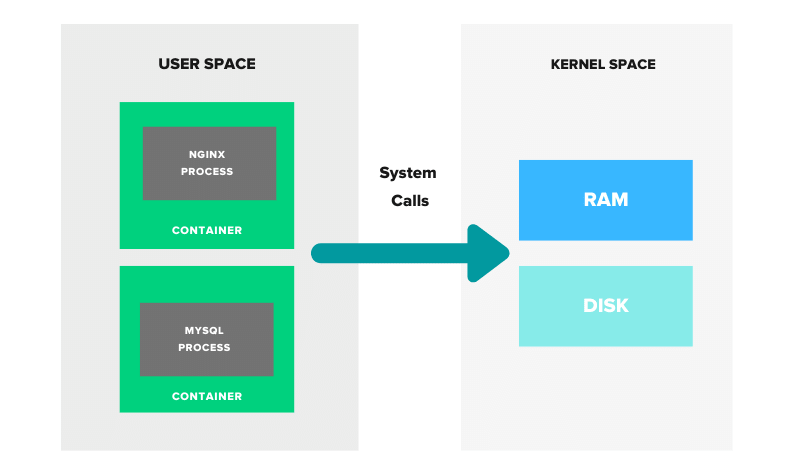
When a container is launched, it starts a process in the host operating system’s kernel. However, it’s important to note that a container is not just a single process – it can contain multiple processes and services running in parallel, all within the same isolated environment.
So, while a container does start as a process, it’s not limited to just a single process. It’s a more complex system that can contain multiple processes and services, making it a more versatile solution for software development and deployment.
For instance, when you start an Nginx service, it initiates a parent Nginx process that spawns child processes like cache manager, cache loader, and workers
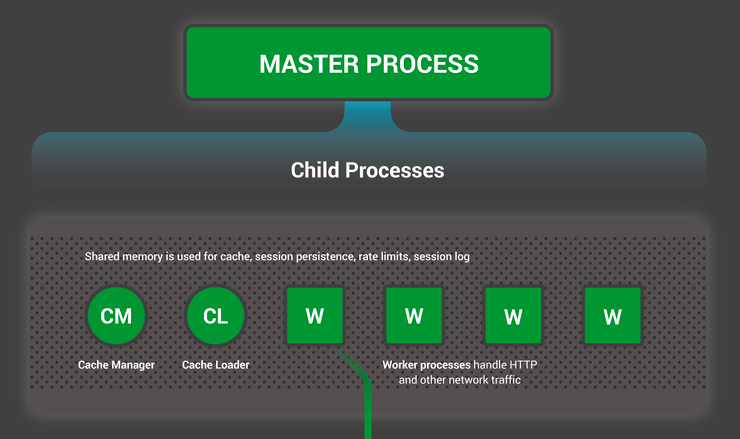
When you start an Nginx container, you’re initiating a master Nginx process in its own isolated environment.
Each container has its own isolated userspace, and you can run multiple containers on a single host. However, it’s important to note that a container does not have the entire operating system.
Unlike a virtual machine with its own kernel, a container only contains the necessary files related to a specific distribution and utilizes the shared host kernel.
In fact, you can run containers based on different Linux distributions on a single host, all sharing the same kernel space. This makes containers a lightweight and efficient solution for running applications in isolated environments.
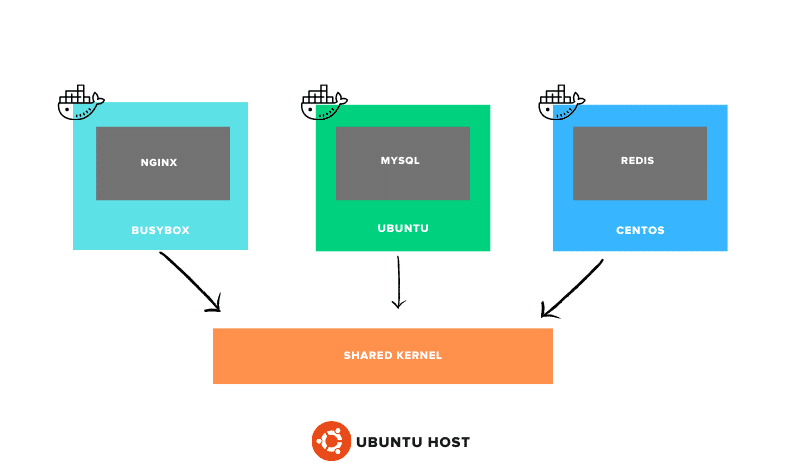
For example, it’s possible to run a container based on RHEL, CentOS, or SUSE on an Ubuntu server. This is because the only difference between Linux distributions is the userspace, whereas the kernel space remains the same
Is Container a Single Process?
Can a container have more than one parent process?
No, a container cannot have more than one parent processes. A container runs a single main process, which is started when the container is initiated. The main process is responsible for starting and managing any child processes that the container needs to run.
Why only one parent process?
Containers are primarily designed to run a single process per container.
The reason for this is to promote isolation and maintain the stability of the container. When a single process is running in a container, any changes or issues related to that process will only affect the container running that process, not other containers or the host system.
For example, let’s say you want to run a web application with a web server and a database. Instead of running the web server and database in a single container, we need to run them in separate containers on the same host.
For instance, if there is a bug or vulnerability in the web server code, it will not affect other containers or the host system, as the web server is isolated within the container.
Similarly, if a change is made to the web server configuration or settings, it will only affect the container running that process and not other containers or the host system. This promotes isolation and maintainability of the container, making it easier to manage and deploy.
Is it possible to run multiple processes inside a container?
It is possible to run multiple processes inside a container by running a process manager, such as supervisord.
The process manager acts as the main process for the container, and it can spawn and manage multiple child processes. This allows multiple services or processes to be run inside a single container, but they are all managed by a single parent process (the process manager).
Namespaces & Control Groups
The isolation of containers is achieved through the use of two key Linux kernel features
- Namespaces and
- Control groups (Cgroups).
A helpful real-world analogy for this concept is an apartment building. Although it is a single large building, each condo or flat is isolated for individual households, with their own identity and metered utilities. This isolation is achieved through the use of concrete, steel structures, and other materials. You cannot see inside other homes unless invited in.
Similarly, in a single host with multiple containers, you need to isolate containers with their own CPU, memory, IP address, mount points, and processes. This is accomplished through the use of namespaces and control groups in the Linux kernel.
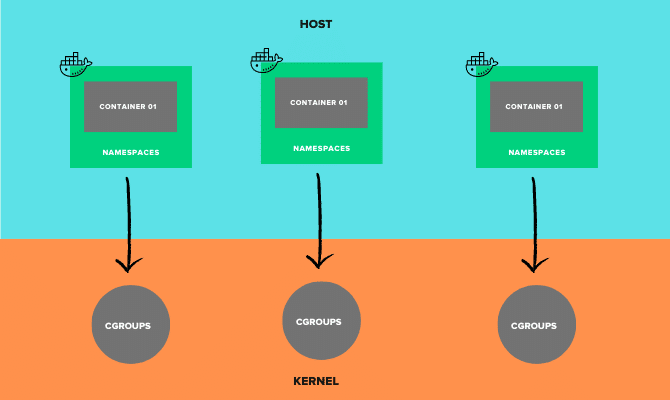
Linux Namespaces
A container is all about having a well-isolated environment to run a service (process).
To achieve that level of isolation, a container should have its file system, IP address, mount points, process IDs, and more. This can be achieved using Linux Namespaces.
The Linux namespace concept was added to Linux kernel version 2.4.19, which was released on December 18, 2002.
Here is what Wikipedia says about Linux Namespaces.
Namespaces are a feature of the Linux kernel that partitions kernel resources such that one set of processes sees one set of resources while another set of processes sees a different set of resources.
The key namespaces in Linux include:
- PID namespace (PID): Responsible for isolating the process (PID: Process ID).
- Network namespace (NET): Manages network interfaces (NET: Networking).
- IPC namespace (IPC): Manages access to IPC resources (IPC: InterProcess Communication).
- Mount namespace (MNT): Responsible for managing the filesystem mount points (MNT: Mount).
- uts namespace (UTS): Isolates kernel and version identifiers (UTS: Unix Timesharing System).
- usr namespace (USR): Isolates user IDs, meaning it separates user IDs between the host and container.
- Control Group namespace(cgroup): Isolates the control group information from the container process.
Using these namespaces, a container can have its network interfaces, IP address, and more. Each container will have its namespace, and the processes running inside that namespace will not have any privileges outside of it.
Essentially, namespaces set boundaries for the containers.
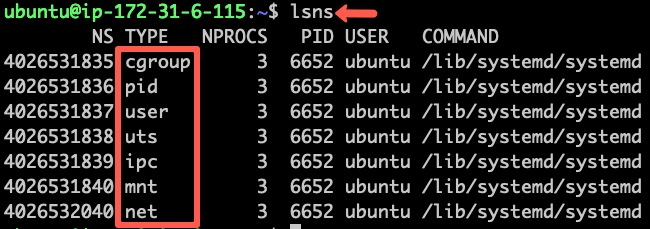
Interestingly, you can list the namespaces in a Linux machine using the lsns command.
Linux Control groups
Starting a service on a Linux system does not require specifying any memory or CPU limits. The kernel automatically allocates resources and prioritizes them for the running services.
However, if you want to set explicit limits on CPU and memory usage for your services, you can use a Linux kernel feature called Control Groups (CGroups).
This is particularly useful when running multiple containers on a single host, as it ensures that resources are not over-utilized by one container at the expense of others.
CGroups manage the resources used by a container and allow you to restrict CPU, memory, network, and I/O resources for a container. Without resource limits, a single container could potentially use all the available host resources, leaving other containers with insufficient resources and causing them to crash.
Thankfully, tools like Docker simplify the process of setting resource limits by abstracting away the complex backend configurations. With Docker, you can easily specify CPU and memory limits using simple parameters, ensuring that your containers run efficiently and reliably.
Evolution of Containers
Containerization is not a new technology, despite what some may think. In fact, Google has been utilizing container technology in its infrastructure for years.
The concept of containers actually dates back to the 1970s with the introduction of chroot, a concept that allowed for the changing of a process's root directory.
Since then, many container-based projects have been developed, with some starting as early as 2000. Here is a list of such projects
| Year | Technology |
| 2000 | FreeBSD jails introduced the container concept. |
| 2003 | Linux-V server project released with the concept of OS-level virtualization |
| 2005 | Solaris Zones- OS-level virtualization project introduced |
| 2007 | Google released a paper on Generic Process Containers |
| 2008 | The initial release of LXC containers |
| 2011 | cloudfoundry announced warden |
| 2013 | lcmcty- Open-sourced by Google |
| 2013 | Docker project was announced by DotCloud |
| 2014 | Rocket. (rkt) announced by CoreOS |
| 2016 | Windows container preview as released as part of Windows server 2016 |
Container Vs Virtual Machies
The following image shows the primary differences between a container and a virtual machine.
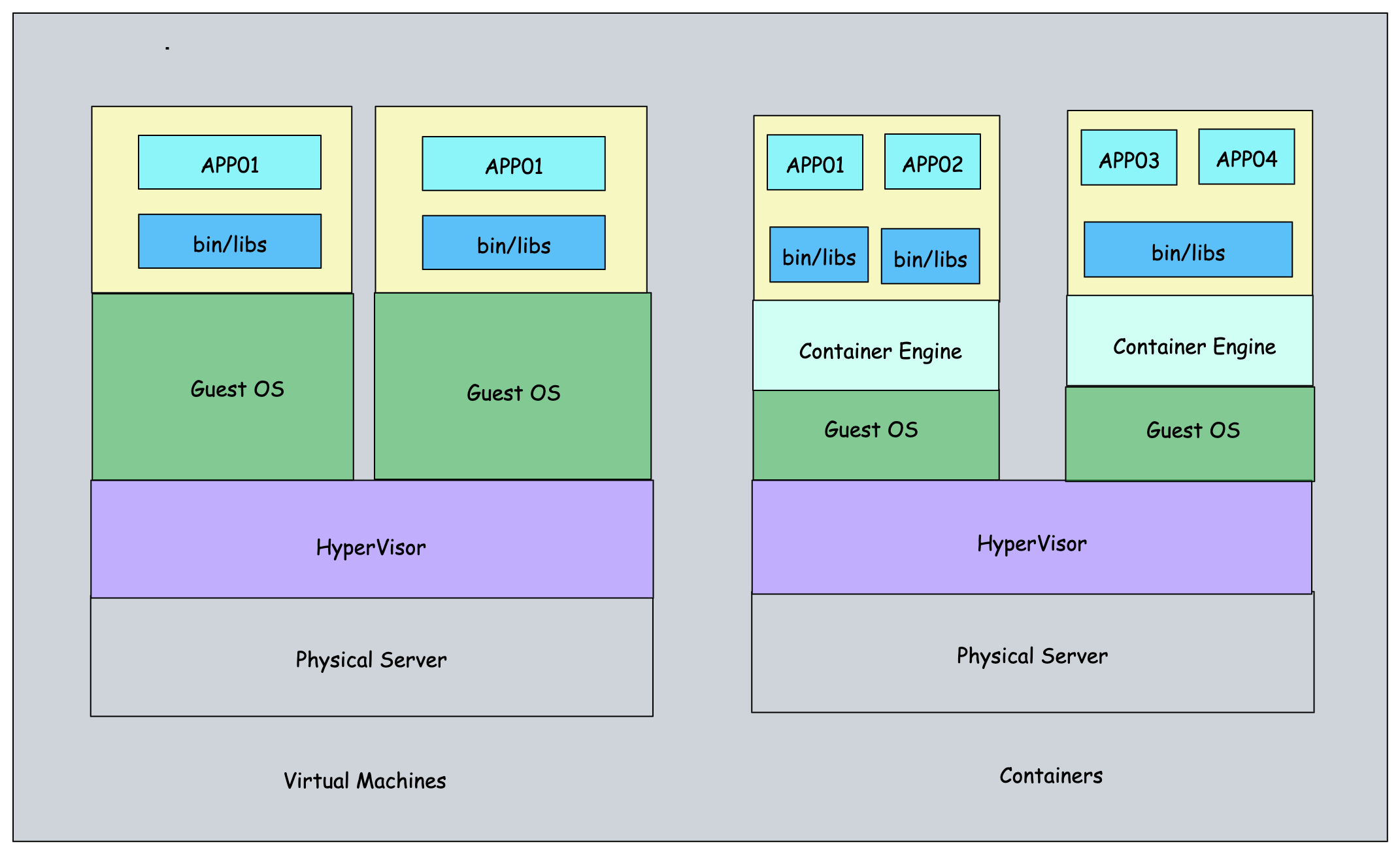
Containers offer several advantages over virtual machines (VMs) that make them a popular choice for deploying applications:
Resource Utilization & Cost:
VMs allow running applications independently, but they can be underutilized and resizing a VM for a production application can be challenging.
In contrast, containers require minimal CPU and memory resources and can run multiple containers inside a VM for better application segregation. Resizing a container takes only seconds, making it more efficient and cost-effective.
Provisioning & Deployment:
Provisioning a VM and deploying applications on it can take minutes to hours, depending on the workflow involved. Even rolling back changes can take time.
In contrast, containers can be deployed in seconds, and rollbacks are equally fast, making them more agile and efficient.
Drift Management:
Managing drift in VMs is difficult, requiring extensive automation and processes to ensure all environments are similar. However, following immutable deployment models can prevent drift in VM environments.
Containers, on the other hand, require only updating the container image for changes. By making changes in the development environment and re-baking the container image, you can ensure that the same image is used in all environments. This makes managing drift easier and more efficient.
Conclusion
In this guide we looked at the core fundamental of container and how it is different from virtual machines.
Next we you can get started with following tutorials.
