

In this blog we will look at,
- Need for Terraform State Locking
- State Locking With DynamoDB
- State Locking with S3 without DynamoDB
- When to use DynamoDB and when to use s3 state locking.
Before we get into the details, let's understand some basics.
So what is state lock?
When we look at real-world Terraform implementations, most Terraform infrastructure deployments happen through CI/CD systems.
This means that, at any given point in time, the same Terraform state could be accessed by different CI/CD jobs. Also, multiple developers could access the same state file during the development process.
If multiple terraform process uses the same state file, it could lead to conflicts and inconsistencies in the state file. (race conditions).
So we need state locking to ensure one terraform process modifies the resource at a time.
It is like putting a "do not disturb" sign on your state file.
Organisations usually store the Terraform state file in an Amazon S3 bucket. This provides a central place that's durable and accessible for the team
Along with S3, a DynamoDB table is set up to manage locks.
State Locking With DynamoDB
In AWS environment, the standard approach is using DynamoDB for state locking.
Here is how DynamoDB state locking works.
- When Terraform wants to modify a resource, it acquires a lock in DynamoDB by creating an entry in DynamoDB table with a specific lock ID (e.g., “lock-abc123”).
- If the lock is successful, terraform gets access to the state file from s3
- Once all the resource modifications are done, Terraform updates the state file and releases the DynamoDB lock.
For example, when developer X executes the terraform code, DynamoDB will lock the state, and developer Y should wait until the execution is completed.
Also, DynamoDB has a timeout period to prevent permanent lock-outs. This is helpful in cases where a lock is acquired by terraform, and it holds the lock due to abnormal process termination.
The following image shows the Terraform s3 backend workflow with DynamoDB locking feature.
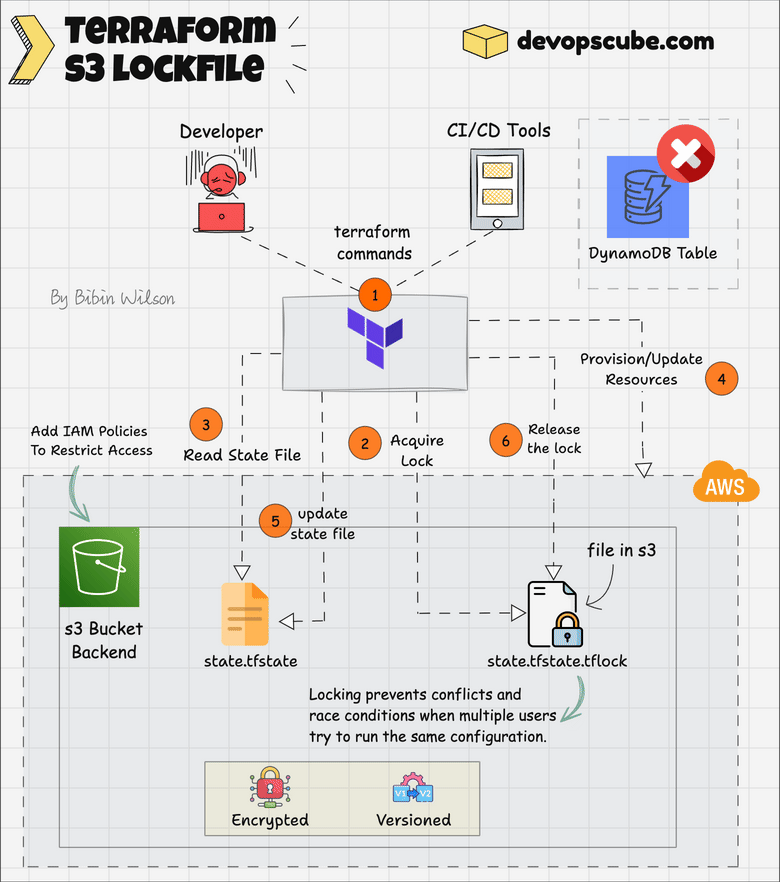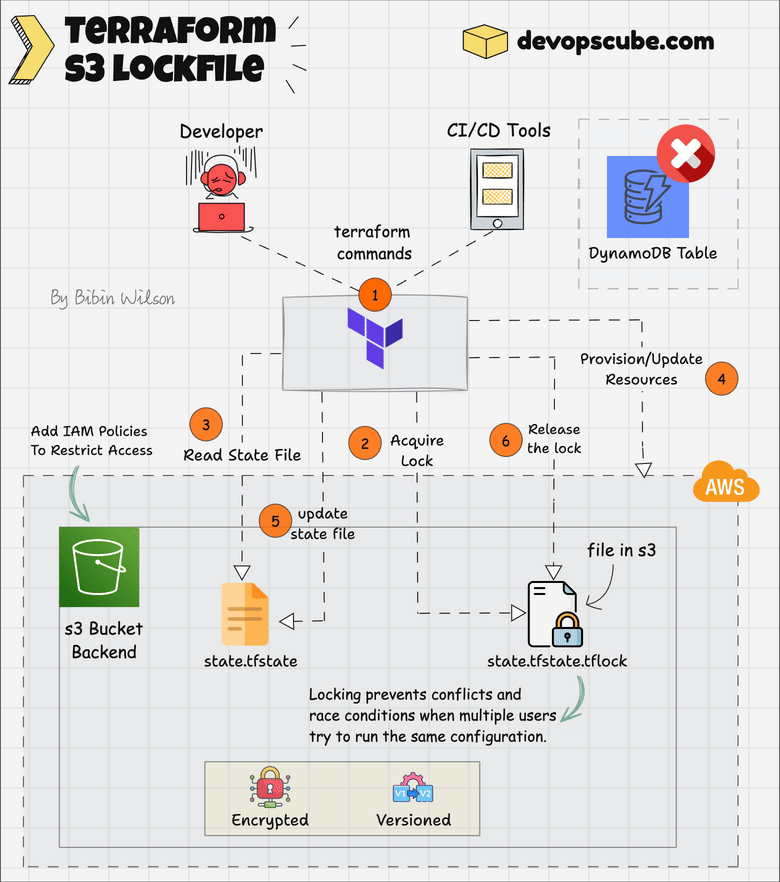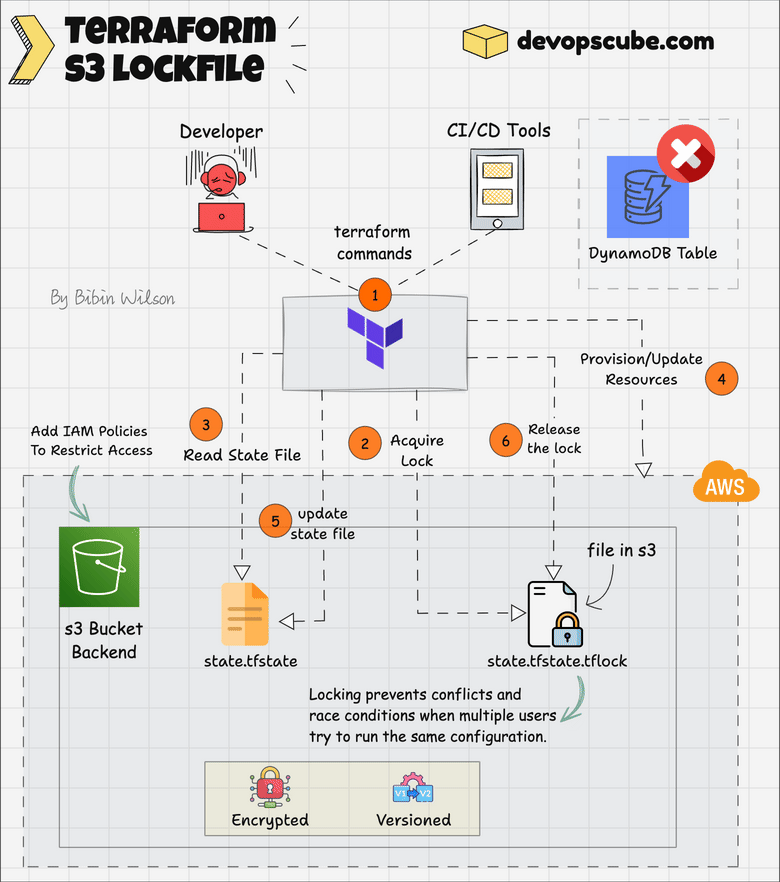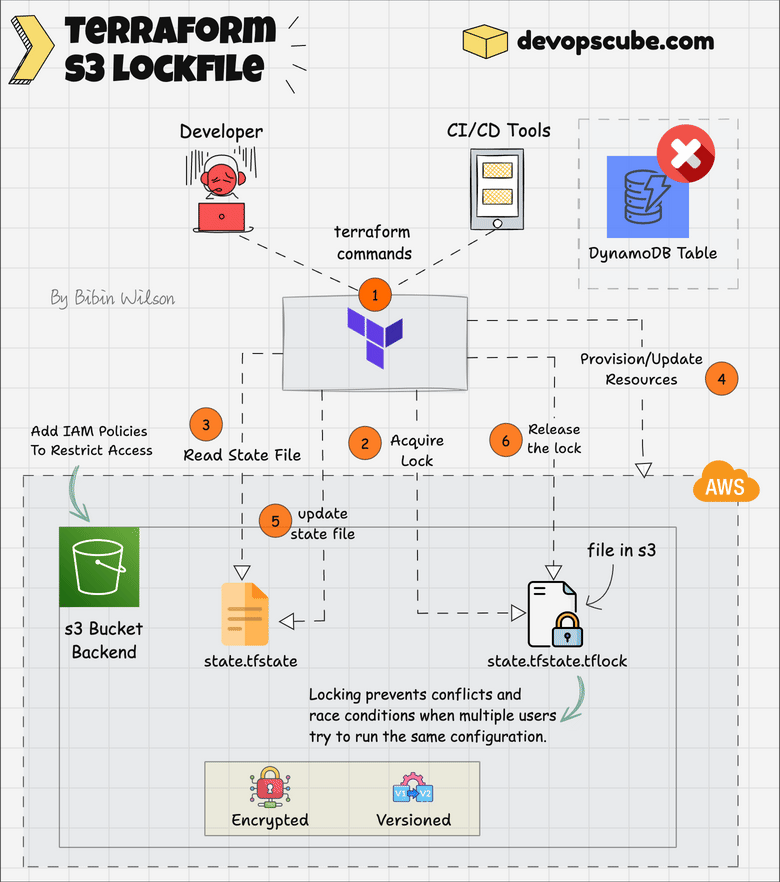
State Locking With s3 Lockfile ( Experimental Feature)
With S3 now supporting conditional writes, it can handle concurrency and state locking.
Conditional writes allow S3 to prevent overwrites unless certain conditions are met. This ensures stronger consistency when multiple processes attempt to update the same S3 object.
For example:
- You can update an object only if it has not changed since the last read.
- This prevents race conditions where two Terraform processes might overwrite the same state file.
The Terraform backend configuration that uses DynamoDB for state looks like this:
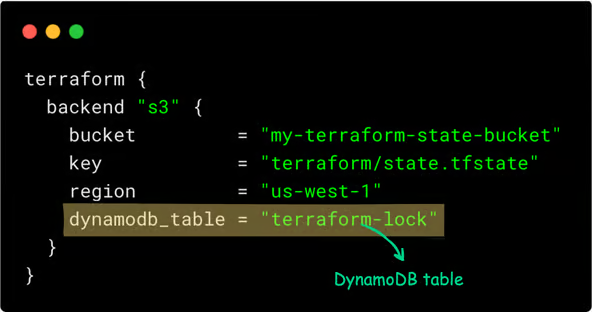
You can replace DynamoDB with an s3 lock using use_lockfile a flag as shown below. (introduced as experimental in Terraform 1.10)

You can copy and add the below backend block in your Terraform code to use the S3 lock.
terraform {
backend "s3" {
bucket = "my-terraform-state-bucket"
key = "terraform/state.tfstate"
region = "us-west-1"
use_lockfile = true
}
}In the above block, update your bucket name, key structure, and region.
Here is how it works.
Terraform creates a .tflock file in S3 before modifying the state to prevent conflicts.
It checks for an existing lock and waits or fails if another process is running. S3’s conditional writes enforce locking.
When you apply the Terraform script, you can see a .tflock file in S3, as shown below.
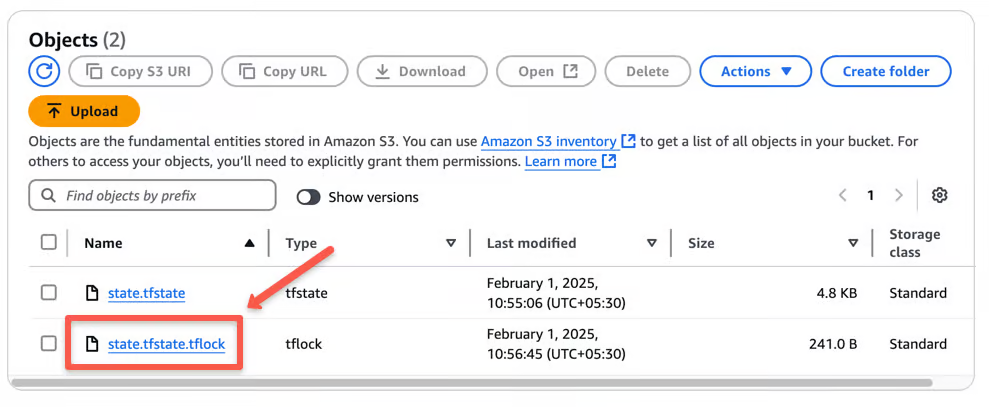
Once done, Terraform deletes the lock file.
If another user tries to apply, they will get an error similar as shown below.
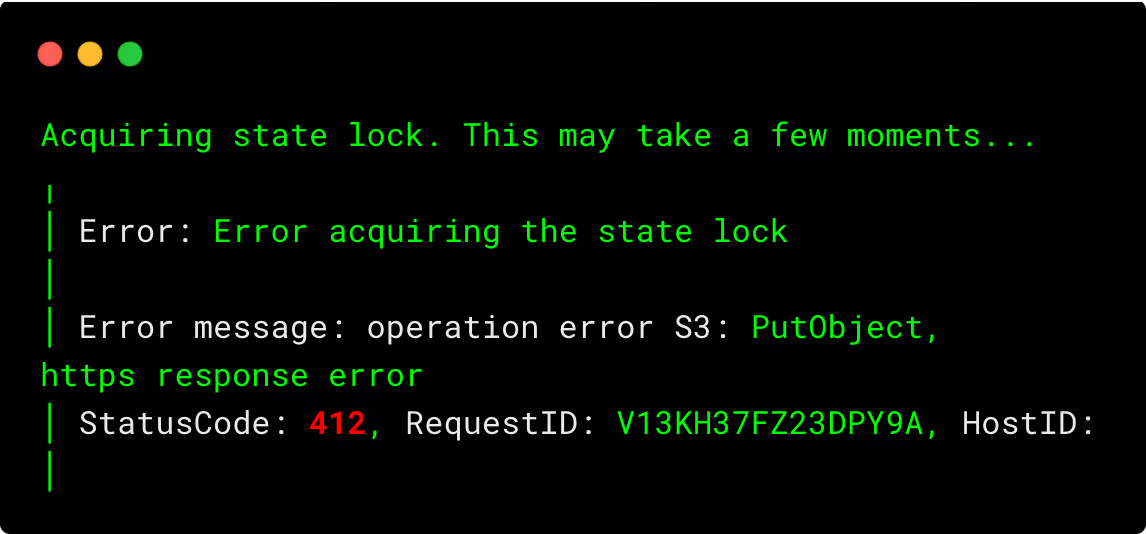
Best Practices
Following are some of the best practices you can follow while using s3 as remote state storage.
- Enable Versioning on the S3 Bucket: Turn on versioning for the S3 bucket. This keeps track of all changes to the state file, allowing you to recover previous versions if something goes wrong
- Set Up Proper Access Controls: Use AWS IAM policies to restrict who can read or write to the S3 bucket and DynamoDB table. This ensures that only authorized team members can make changes.
- Encrypt the State File: Enable encryption for the state file stored in S3. This protects sensitive information from unauthorized access.
- Handle Locking Issues Carefully: If a Terraform process ends unexpectedly, it might leave a lock in place. Terraform provides a command to manually remove such locks, but use it cautiously to avoid conflicts.
- Organize State Files Clearly: For different projects or environments (like development and production), use separate state files. This reduces the risk of accidental changes affecting the wrong environment.
Conclusion
Replacing DynamoDB with use_lockfile simplifies your Terraform setup but comes with some trade-offs. Also, it is an experimental feature.
So when should you consider using use_lockfile?
- If you want a simpler setup without additional AWS resources.
- If cost is a concern and you don’t want to maintain a DynamoDB table.
- If your Terraform runs are infrequent and don’t need high concurrency control. Because S3 locking is eventually consistent, it could theoretically lead to race conditions in high-concurrency scenarios.
When to Stick with DynamoDB
- If you have multiple teams working on the same Terraform state file.
- If you need stronger locking guarantees with high-frequency Terraform operations. Because DynamoDB provides stronger consistency guarantees and better handling of edge cases (like process crashes).
- Also, DynamoDB locking is more battle-tested, while S3 native locking is simpler but newer.
To use DynamoDB for Terraform Statelock, refer to this detailed blog.
Share your thoughts in the comments below!
Want to Stay Ahead in DevOps & Cloud? Join Free Newsletter Below.