
In this Python Web Scrapping Tutorial you will learn about python web scrapping techniques using python libraries.
One of the most important things in the field of Data Science is the skill of getting the right data for the problem you want to solve. Data Scientists don't always have a prepared database to work on but rather have to pull data from the right sources. For this purpose, APIs and Web Scraping are used.
- API (Application Program Interface): An API is a set of methods and tools that allows one's to query and retrieve data dynamically. Reddit, Spotify, Twitter, Facebook, and many other companies provide free APIs that enable developers to access the information they store on their servers; others charge for access to their APIs.
- Web Scraping: A lot of data isn't accessible through data sets or APIs but rather exists on the internet as Web pages. So, through web-scraping, one can access the data without waiting for the provider to create an API.
What is Web Scraping?
Web scraping is a technique to fetch data from websites. While surfing on the web, many websites don’t allow the user to save data for private use.
One way is to manually copy-paste the data, which both tedious and time-consuming.
Web Scraping is the automatic process of data extraction from websites. This process is done with the help of web scraping software known as web scrapers.
They automatically load and extract data from the websites based on user requirements. These can be custom built to work for one site or can be configured to work with any website.
One classic real world use case for web scrapping is, price comparison apps and websites. The data provided by these websites are scrapped from multiple e-commerce websites.
Why Python for Web Scrapping?
There are a number of web scraping tools out there to perform the task and various languages too, having libraries that support web scraping.
Among all these languages, Python is considered as one of the best for Web Scraping because of features like – a rich library, easy to use, dynamically typed, etc.
Python Web Scrapping Libraries
Here are some most commonly used python3 web Scraping libraries.
- Beautiful Soup
- Selenium
- Python Requests
- Lxml
- Mechanical Soup
- Urllib2
- Scrapy
Now discuss the steps involved in web scraping using the implementation of Web Scraping in Python with Beautiful Soup.
How to Build Web Scraper Using Python?
In this section, we will look at the step by step guide on how to build a basic web scraper using python Beautiful Soup module.
- First of all, to get the HTML source code of the web page, send an HTTP request to the URL of that web page one wants to access. The server responds to the request by returning the HTML content of the webpage. For doing this task, one will use a third-party HTTP library called requests in python.
- After accessing the HTML content, the next task is parsing the data. Though most of the HTML data is nested, so it's not possible to extract data simply through string processing. So there is a need for a parser that can create a nested/tree structure of the HTML data. Ex. html5lib, lxml, etc.
- The last task is navigating and searching the parse tree that was created using the parser. For this task, we will be using another third-party python library called Beautiful Soup. It is a very popular Python library for pulling data from HTML and XML files.
Step 1: Import required third party libraries
Before starting with the code, import some required third-party libraries to your Python IDE.
pip install requests
pip install lxml
pip install bs4Step 2: Get the HTML content from the web page
To get the HTML source code from the web page using the request library and to do this we have to write this code. I am taking this webpage.
source = requests.get('https://devopscube.com/project-management-software').textStep 3: Parsing the HTML content
Parse the HTML file into the Beautiful Soup and one also needs to specify his/her parser. Here we are taking lxml parser.
soup = BeautifulSoup(source, 'lxml')To print the visual representation of the parse tree created from the raw HTML content write down this code.
print(soup.prettify())Step 4: Navigating and searching the parse tree
Now, we would like to extract some useful data from the HTML content. The soup object contains all the data in a nested structure that could be programmatically extracted. In our example, we are scraping a web page contains a headline and its corresponding website.
We can start parsing out the information that we want now just like before. Let's start by grabbing the headline and its official website.
So to grab the first headline and its official website for the first post on this page let's inspect this web page and see if we can figure out what the structure is.
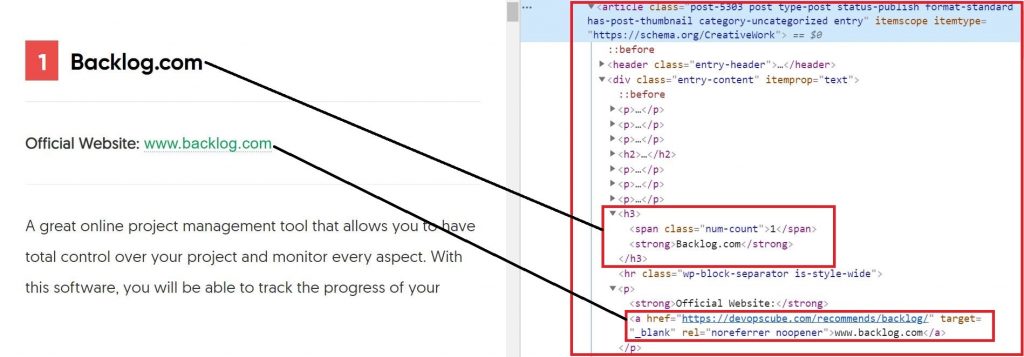
From the above diagram, you can see that the whole content including the headline and the official website is under the article tag. So let's start off by first grabbing this entire first article that contains all of this information.
article = soup.find('article')Now let's grab the headline. So if we look in the HTML source code, we have our <div> tag and within that <h3> tag the headline is present. So the code for grabbing the headline is
headline = article.div.h3.text
print(headline)Output:
Backlog.com
Next, let's grab the website. So if we look in the HTML source code, we have our <div> tag with its class = "entry-content" and inside that, we have a link inside <a> tag and the text of that link contains the official website. So the code for grabbing the website is
offcialWebsite = article.find('div', class_='entry-content').a.text
print(offcialWebsite)Output:
www.backlog.com
The complete python web scrapping code is given below.
# Python program to illustrate web Scraping
import requests
from bs4 import BeautifulSoup
import lxml
source = requests.get('https://devopscube.com/project-management-software').text
soup = BeautifulSoup(source, 'lxml')
article = soup.find('article')
headline = article.div.h3.text
print(headline)
offcialWebsite = article.find('div', class_='entry-content').a.text
print(offcialWebsite)Output:
Backlog.com www.backlog.com
Realworld Python Web Scrapping Projects
Here are some real world project ideas you can try for web scrapping using python.
- Price monitoring in e-commerce websites
- News syndication from multiple news websites and blogs.
- Competitor content analysis
- Social media analysis for trending contents.
- COVID-9 data tracker
Also look at some of the python web scrapping examples from Github.
Important Note: Web scraping is not considered good practice if you try to scrape web pages without the website owner's consent. It may also cause your IP to be blocked permanently by a website.
Python Web Scrapping Courses
If you want to learn full-fledged web scraping techniques, you can try the following on-demand courses.
- Web Scraping in Python [Datacamp - Check Datacamp discounts for latest offers]
- APIs and Web Scraping in Python - [Check DataQuest Coupons for latest offers]
- Predictive Data Analysis With Python
- Web scrapping courses [Udemy]
- Using Python to Access Web Data [Coursera]
Conclusion
So, in this python web scraping tutorial, we learned how to create a web scraper. I hope you got a basic idea about web scraping and understand this simple example.
From here, you can try to scrap any other website of your choice.
Also, if you are starting your coding journey, checkout 30+ top websites to learning coding online.