

Kubernetes community started offering several built-in features to deploy, manage, and scale AI/ML applications efficiently.
In this blog, I will keep a track on all the native AI/ML features offered by Kubernetes (Alpha, Beta and GA features)
Kubernetes Device Plugins (Stable)
By default, Kubernetes has no idea what a GPU is.It only understands resources like CPU and memory.
GPUs are a key requirements for AI and ML applications.To make K8s aware of GPUs, you need the device plugin framework.
It’s basically a set of APIs that allows third-party hardware vendors like NVIDIA to create plugins that advertise specialized hardware to the K8s scheduler.
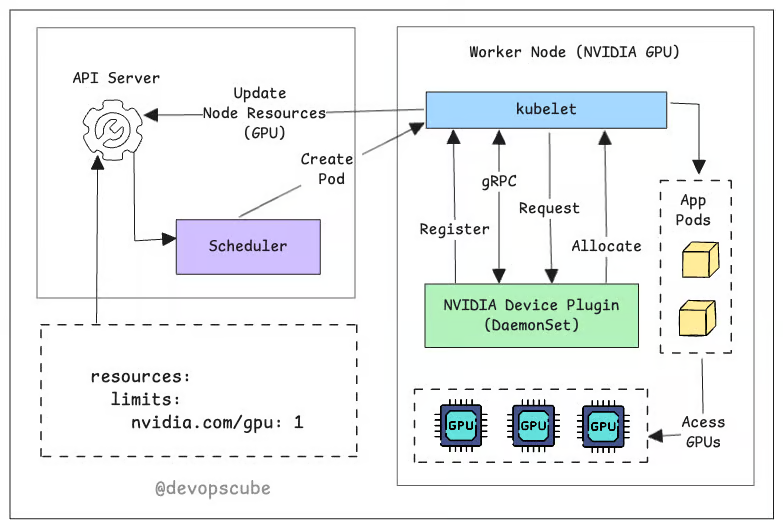
Here’s how it works:
- Device plugins run on specific nodes (usually as DaemonSets). It registers with kubelet and communicates via gRPC.
- They let nodes advertise their hardware (like NVIDIA or AMD GPUs) to the kubelet.
- The kubelet shares this information with Kubernetes, so the system knows which nodes have GPUs.
Once the device plugin is set up, you can request a GPU in your Pod spec, like this:
resources:
limits:
nvidia.com/gpu: 1The scheduler sees your GPU request and finds a node with available NVIDIA GPUs and the pod gets scheduled to that node.
Once scheduled, the Kubelet invokes the device plugin's Allocate() method to reserve a specific GPU. The plugin then provides the necessary details, such as the GPU device ID. Using this information, the Kubelet launches your container with the appropriate GPU configurations.
The following image illustrates the complete workflow of device plugins.
For example, you can use GPU nodes with EKS using Nvidia device plugins.
Gateway API Inference Extension
Traditional load balancers treat all traffic equally based on URL paths or round‑robin rules.
But large language models (LLMs) are different:
- They run for longer (seconds to minutes).
- They often hold things in memory (like token caches or adapters).
- Some requests need low latency (e.g., chat) while others can wait (e.g., batch).
Instead of treating AI model workloads like normal web traffic, Gateway API Inference Extension (built on top of Kubernetes’ Gateway API) adds model-aware routing to AI inference workloads.
- It routes based on model identity, readiness, and request urgency.
- It helps Kubernetes use GPUs more smartly and serve requests faster.
One of the key features it enables is body-based routing, where the system inspects the actual request body (like JSON payloads) to determine how and where to route the request.
This is especially useful for LLM workloads, where critical information like model name, priority, or task type often lives in the request body rather than the URL.
Mounting Container Images as Volumes (Beta)
Kubernetes version 1.31 has introduced a new alpha feature that allows you to use OCI image volumes directly within Kubernetes pods.
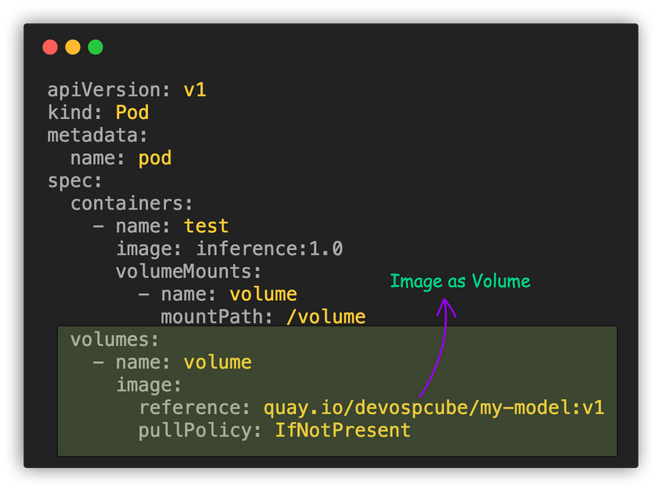
OCI images are images that follow Open Container Initiative specifications. You can use this feature to store binary artifacts in images and mount them to pods.
This is particularly useful for ML projects dealing with LLMs. Large Language Model deployment often involves pulling models from various sources like cloud object storage or other URIs.
OCI images containing model data make it much easier to manage and switch between different models. One project already experimenting with a similar feature is KServe, which has a feature called Modelcars.
Modelcars allows you to use OCI images that contain model data. With native OCI volume support in Kubernetes, some of the current challenges are simplified, making the process smoother.
Other Kubernetes Community Projects
The following projects are maintained by the official Kubernetes community to address key challenges in managing AI/ML workloads on Kubernetes:
1. JobSet
When training big AI models, the job is split across many machines (GPU nodes). All parts (called workers) need to start at the same time and stay in sync. If one worker fails, the training state may get corrupted, and you may have to start over.
JobSet API solves this by coordinating multiple interconnected jobs that must work together as a single unit. It helps start, manage, and recover all these connected jobs together.
2. Kueue
When multiple teams compete for expensive GPU resources, jobs often wait inefficiently or get scheduled to suboptimal hardware. Teams face unfair resource allocation and GPU resources sit idle while jobs queue poorly.
Kueue helps fix this by:
- Using queues with priorities, so more important jobs go first
- Being aware of the hardware layout (topology), so it picks the best GPUs for each job
- Making sure all teams get a fair share of the GPU resources
3. LeaderWorkerSet
When AI models are too big to run on one machine, you need to break them into parts and run them across multiple GPUs or nodes. But doing that is hard.
You have to:
- Set up each deployment manually
- Handle complex networking
- Make sure all parts know how to find and talk to each other (called service discovery and coordination)
LeaderWorkerSet makes this easier. It gives you one simple API to deploy the full setup. It:
- Automatically handles the networking
- Coordinates everything
- Treats the whole thing as one unit
This saves time and reduces errors when running large AI models across many machines.
Conclusion
I have covered the key AI/ML features of Kubenretes.
If you are looking to get started with MLOps on Kubernetes, check out our guide on deploying models on Kubernetes with KServe.