

When we talk about how AI understands language, one big question is how it can recognize that words like "king" and "queen" are related even though the words do not match exactly?
The answer lies in a powerful concept called embeddings.
Embeddings are a way of translating words, images, or even pieces of code into numbers (nothing but vectors). Not just random numbers, but numbers that capture meaning and relationship between words.
Why does this matter? Because embeddings are the foundation of modern AI. As a DevOps engineer or ML engineer, if you work with AI in projects, you will come across embeddings sooner or later.
In this blog, I explained the following.
- What are embeddings and a bit of their history.
- How do they understand context and meaning.
- The most common types of embeddings.
- Real-world use cases
- Tools and APIs you can try yourself.
Lets dive in!
What are Embeddings?
Embeddings are a numerical representation of text that converts words, sentences, or even entire documents into vectors that computer can understand.
For example, "I love Kubernetes" becomes something like [0.12, -0.45, 0.88, …]
So, instead of treating words like symbols, embeddings capture their meanings.
Think of embeddings as plotting every word or sentence as a point in multi-dimensional space. Words that are similar in meaning are placed close together.
The following image illustrates how embeddings are created. All the data is sent to a embedding model and it converts data in to numbers.
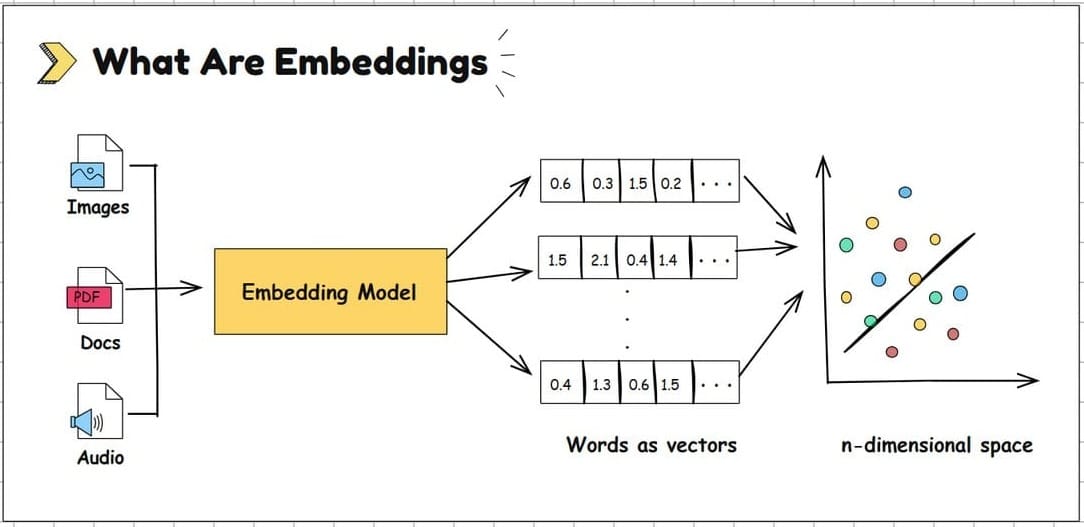
For example, "login problem" and "can't access my account" would placed together on dimensional space, even though they use different words.
But here is the key question.
How exactly embeddings capture meaning?
Lets understand that in the next section.
How do Embeddings Understand Context
Embeddings are created using deep learning models that are trained on huge amounts of texts from books, internet articles, websites and more.
text-embedding-3-small embedding model that convert text into vector numbers.These models learn by reading sentences and noticing patterns like which word often appear together and how their meaning changes depending on its surrounding words.
For example,
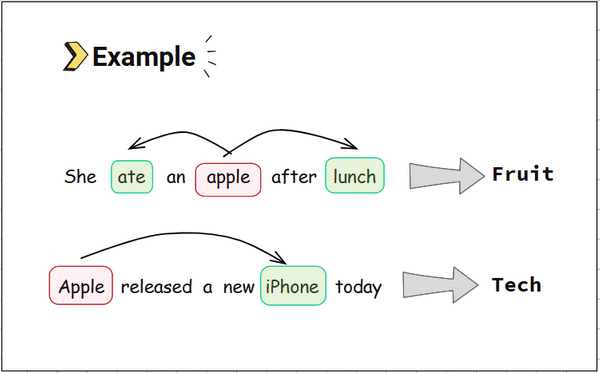
- In "bank of river", the word bank means riverbank.
- In "bank account", the word bank is financial institution
The model learns to give each bank a different vector based on its context.
Models like Word2Vec, GloVe, BERT and Transformers do this by learning from tasks such as:
- Predicting a missing word in a sentence like example of "the cat __ on the mat"
- Identifying which sentences are similar and
- Understanding the topic or sentiment of text.
Over time as they train on billions of words, these models become very good at capturing how words relate and interact. This is how embeddings "understand" the language.
Let's look into the history of how embeddings came into existence.
History of Embeddings
Embeddings didn't just appear overnight they evolved over time.
In the early 2010s, traditional machine learning models used one-hot encoding, a very basic word-to-number method, which didn't capture meaning.
Then in 2013, Google introduced Word2Vec, a model that changed everything by teaching the computer to learn from context. This model tries to predict a word based on its neighbours.
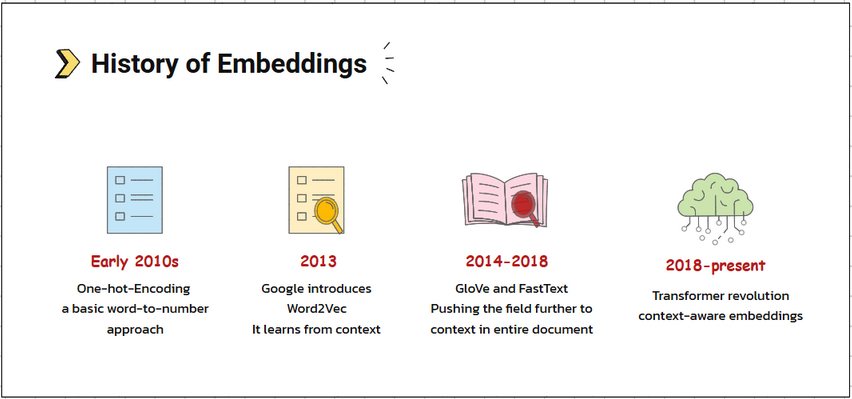
Then, between 2014 - 2018 models like GloVe (Stanford), FastText (Facebook) pushed the field further.
- GloVe looks at entire documents to find word relationships, not just local context like word2vec.
- FastText, instead of treating a word as a whole, it breaks it into sub-words or character chunks. It can handle new words, misspellings or variations better than Word2Vec or GloVe.
For example, "playing" breaks down into "play", "lay", "ying".
From 2018 to present, came the transformer revolution. Google's BERT, OpenAI's GPT, and newer transformer-based models took embeddings to the next level. They generate context-aware embeddings, meaning the same word has different vectors depending on how it is used.
For example BERT,
- Considers context from both directions simultaneously.
- Learns the meaning of a word based on its surroundings.
- Generates different embeddings for the same word used differently
Whereas OpenAI GPT models,
- Similar idea, but focuses on generating text, not just understanding it.
- Learns deeper patterns by predicting the next word across huge text datasets.
Without embeddings, AI would struggle to make sense of the vast amount of unstructured data like text, images, or audio.
In short, embeddings allow AI to understand context and meaning. They are the foundation of modern AI systems, from GPTs to search engines to voice assistants.
Common Types of Embeddings
When converting the data into vectors, different types of embeddings help machines to understand and interpret information more effectively.
Let's explore the types of embeddings and how they are used.
1. Word Embeddings
These represent individual words as vectors that capture their meanings and relationships.
For example, "king" is to "man" and "queen" is to "woman".
Use Cases were word similarity, analogy reasoning, keyword clustering.
Popular models are,
- Word2Vec (Google)
- GloVe (Stanford)
- FastText (Meta)
- text-embedding-3-small / large (OpenAI)
2. Sentence & Document Embeddings
These represent entire sentences or paragraphs to capture overall meaning rather than individual words.
Use cases were semantic search, document retrieval, summarization, clustering.
Popular models are,
- Sentence-BERT (SBERT)
- Universal Sentence Encoder (Google)
- Doc2Vec
- InferSent (Facebook)
3. Contextual Embeddings
Unlike Word2Vec which gives one fixed vector per word, contextual embeddings will change based on the sentence context.
For example, "bank in river" implies the model that "bank' here is "river bank (water)" and its vector is different compared to sentence "bank account", the bank will have different vector embedding.
Use cases were named-entity recognition, question-answering.
Popular models are,
- ELMo (Embeddings from Language Models)
- BERT / RoBERTa / ALBERT
- GPT family (OpenAI)
4. Image Embeddings
Converts images into vectors that capture visual features like colors, shapes, and textures. These are widely used in:
Use cases were image search, caption generation, visual similarity, multimodal AI.
Popular models:
- ResNet
- CLIP (OpenAI)
- Google’s Vision AI
5. Graph embeddings
Graph embeddings represent nodes as vectors. They capture relation and structure that is similar like social network.
For example, Users (nodes) are connected or have similar friends will have similar embeddings. These embeddings help in link, prediction, node classification, recommendation and community detection.
Use cases: Social network analysis, recommendation systems, fraud detection.
Popular models are,
- Node2Vec
- GraphSAGE
6. Multimodal Embeddings
Combine text, image, audio, and other data into a shared embedding space.
Use cases were search engines that understand text + image queries, or AI assistants that process multiple data types.
Popular models are,
- CLIP (OpenAI)
- Flamingo (DeepMind)
- Gemini (Google DeepMind)
Real World Examples
Now that we have looked in to the technical details of embeddings, lets explore real world use cases of how these embeddings were used. This you you will be able to relate to it.
Amazon uses product embeddings to understand relationships between items even when their titles, brands or categories differ. This is what drives the "customers who viewed this item also viewed" section on Amazon app.
This powers features like "customers who viewed this also viewed." According to Amazon Science, their embedding-based GNN approach outperformed previous methods by 30% to 160%.
Spotify uses embeddings as the foundation of its recommendation system. Every artist, track, listener, and playlist has an embedding, a numerical fingerprint that captures its characteristics.
With over 667 million playlists used for daily training, Spotify creates a "Cloud of Similarities" where similar content clusters together, powering features like Discover Weekly.
Embeddings are also used in AI writing assistants such as Notion AI and Grammarly. By embedding entire documents, these tools can understand semantic context to offer contextual rephrasing suggestions, retrieve related notes or references and summarizing long content.
After seeing how companies like Amazon, Spotify, and Grammarly use embeddings in the real world, you might be wondering how are these embeddings actually created? Or what tools do they use to build them?
Let’s take a look in the next section.
Tools & APIs to Try Out
If you are curious to try embeddings yourself, there are several tools available.
- The OpenAI Embeddings API offers high-quality embeddings with a simple interface, perfect for developers getting started.
- Cohere Embed is another strong option, known for being fast and cost-effective for generating text embeddings.
- For open-source enthusiasts, Hugging Face Transformers provides a wide selection of pre-trained models that can generate embeddings for various data types.
- Once you have embeddings, you will need a place to store and search them using tools like Pinecone, Weaviate, and Qdrant, which are powerful vector databases built specifically for this.
- And if you are looking to build RAG-based applications or intelligent chatbots, frameworks like LangChain and LlamaIndex make it easy to integrate embeddings into your pipelines.
Conclusion
Embeddings are like the secret language that helps AI understand the world. They turn words and images into numbers that carry meaning.
That is why AI can tell that "king" and "queen" are related. These connections don't come from memorizing words. They come from how embeddings map meaning into a space where similar ideas live close together.
Over time, embeddings have grown smarter. Early methods like Word2Vec and GloVe helped computers learn from word patterns. Then came advanced models like FastText, BERT, and GPT, which understand not just individual words but also their context.
Today, embeddings power almost everything in AI such as search engines, chatbots, recommendation systems and even writing tools like Grammarly or Notion AI. They help machines understand, organize, and generate information in a way that feels natural to us.
In my upcoming blogs, I will explain more about how embeddings can be used in RAG. I will also show this practically using the application I am building.
If you have any doubts about embeddings, please let me know in the comments.
