

In this blog, we’ll explore split-brain scenario with real world practical examples.
We will look at quorum concepts, and a practical example of how etcd prevents split brain scenario using the Raft consensus algorithm.
I’ll also share a real-world experience with GlusterFS split-brain and the lessons learned.
- Split-Brain Scenario in Distributed Systems
- Quorum in Distributed Systems
- How etcd avoids split brain scenario (Real World example)
Whenever we deploy distributed systems that deal with data, we usually deploy the nodes in different availability zones or different data centers (for on-prem environments) to ensure high availability.
Example: databases like MongoDB, distributed storage systems like GlusterFS, and consensus-based clusters like etcd.
Let’s consider an example of an etcd cluster.
Assume we have a 5-node etcd cluster. To maintain high availability, three nodes are deployed in Zone 1, while the remaining two are placed in Zone 2.
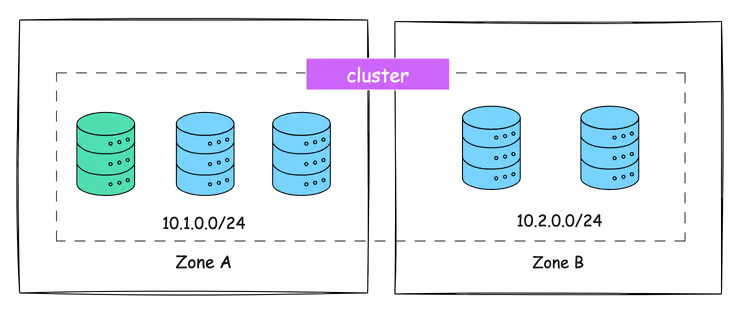
This setup ensures that even if one zone goes down, there are still active nodes in another zone, maintaining service continuity.
Split-Brain Scenario in Distributed Systems
In distributed systems, a split-brain scenario occurs when a group of nodes loses communication with each other, typically due to network partitioning.
For example, in our 5-node etcd cluster, if network connectivity is lost between Zone 1 and Zone 2, the three nodes in Zone 1 may continue operating, forming a majority quorum.
However, the two nodes in Zone 2 might also assume they should continue functioning independently, creating a second, conflicting cluster.
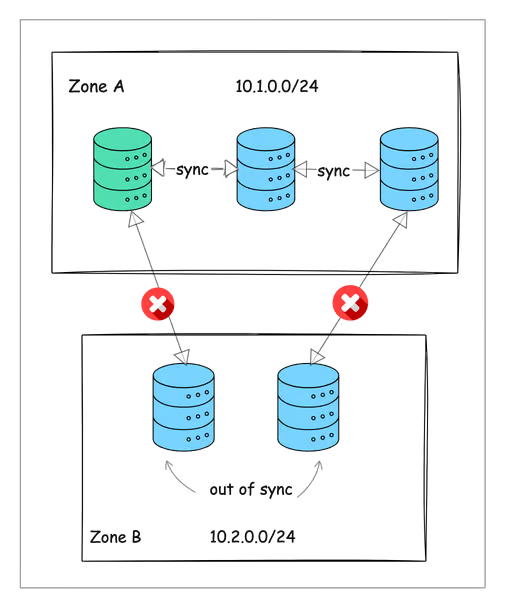
This results in a classic split-brain problem, where:
- Some nodes keep working and accept new data. Other nodes, cut off from the majority, also keep working, but they don’t know what the other side is doing.
- Since both sides are writing new data separately, they don’t match anymore.
- When the network issue is fixed, these nodes may struggle to catch up, leading to wrong or missing data.
Quorum in Distributed Systems
To prevent Split-Brain scenarios, distributed systems use quorum-based decision-making to ensure consistency.
Let us understand the concept of Quorum with examples.
When you deploy database clusters, there are two key patterns:
- Single-Primary Node: All writes go to the primary node, which then replicates those changes to secondary nodes.
- Multi-Primary Node: In this setup, multiple nodes can accept writes simultaneously. When you write to any primary node, that node coordinates with others to ensure the write is properly replicated.
So how do we choose the primary node?
Most distributed databases use a leader election mechanism to determine the primary node. A classic example is etcd’s Raft consensus algorithm.
It works like a voting process: to elect a leader, a candidate node must receive a majority of votes.
For example, in a 5-node system, at least 3 nodes must agree before any decisions can be made. This majority group is called a quorum.
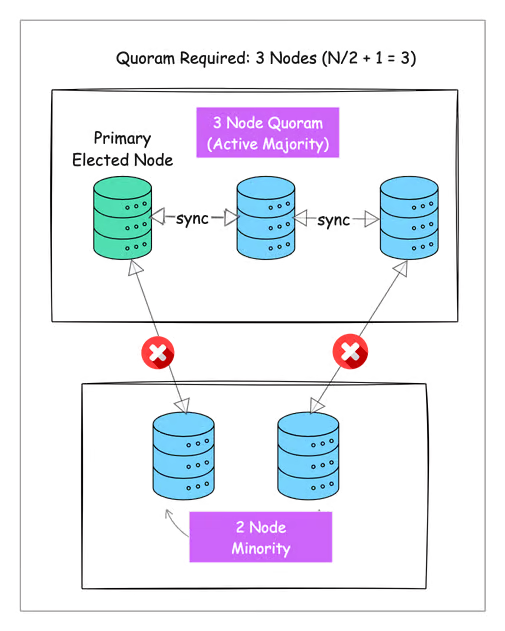
A quorum is typically calculated as (N/2 + 1) where N is the total number of nodes in your system. This ensures that you always have a majority.
For example:
- In a 5-node system, you need 3 nodes to form a quorum (5/2 + 1 = 3)
- In a 7-node system, you need 4 nodes (7/2 + 1 = 4)
Thats why clusters are usually deployed with an odd number of servers, starting from 3, to ensure that a majority (quorum) can always be formed.
Real World Scenario (etcd)
According to the official etcd documentation, split-brain scenarios are effectively avoided in etcd.
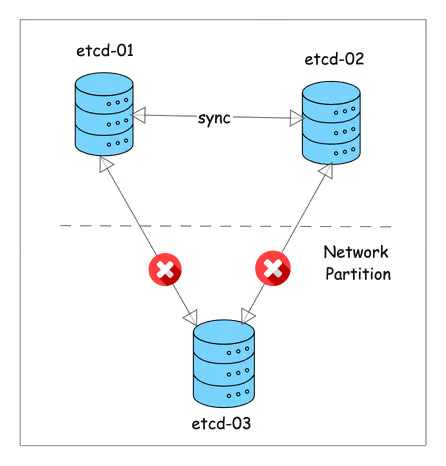
Here's how:
- When a network partition occurs, the etcd cluster is divided into two segments: a majority and a minority.
- The majority segment continues to function as the available cluster, while the minority segment becomes unavailable.
- If the leader resides within the majority segment, the system treats the failure as a minority follower failure. The majority segment remains operational with no impact on consistency.
- If the leader is part of the minority segment, it recognizes that it is separated due to the loss of communication with a majority of the nodes in the cluster and it steps down from its leadership role.
- The majority segment then elects a new leader, ensuring continuous availability and consistency.
- Once the network partition is resolved, the minority segment automatically identifies the new leader from the majority segment and synchronizes its state accordingly.
This design ensures that etcd maintains strong consistency and prevents split-brain scenarios, even in the face of network issues.
You might ask, how does etcd determine if a node is in the majority or minority during a network partition?
Each etcd node knows the total number of nodes in the cluster as part of its configuration. This is stored in the etcd membership list, which tracks:
- Total cluster size (N)
- Node IDs and addresses
- Current leader (if elected)
Nodes regularly send messages (heartbeats) to confirm which nodes are still reachable. After detecting a partition, each node checks how many other nodes it can still talk to.
It compares this number with the quorum requirement (N/2 + 1).
If a node can still communicate with at least quorum (N/2 + 1) nodes, it knows it is in the majority.
If it cannot reach quorum, it realizes it is in the minority and stops making decisions.
Conclusion
For DevOps engineers, understanding split-brain scenarios is important for maintaining reliable distributed systems.
Since modern applications rely on distributed databases, storage systems, and consensus-based clusters, handling network partitions and quorum failures effectively is essential.
DevOps teams must proactively implement strategies to prevent split-brain, ensuring data consistency, availability, and overall system resilience.
If you have any doubts about this blog, drop it on the comment!
Want to Stay Ahead in DevOps & Cloud? Join the Free Newsletter Below.