

In the era of cloud computing, there are many managed MySQL solutions available. However, due to data compliance, and other audit requirements, we will have to choose self-managed solutions. In such cases, a MySQL master-slave replication offers data replication on multiple nodes for scalability and data availability.
MySQL Master-Slave Replication Architecture
In this section, we will look at the MySQL replication architecture and how it works.
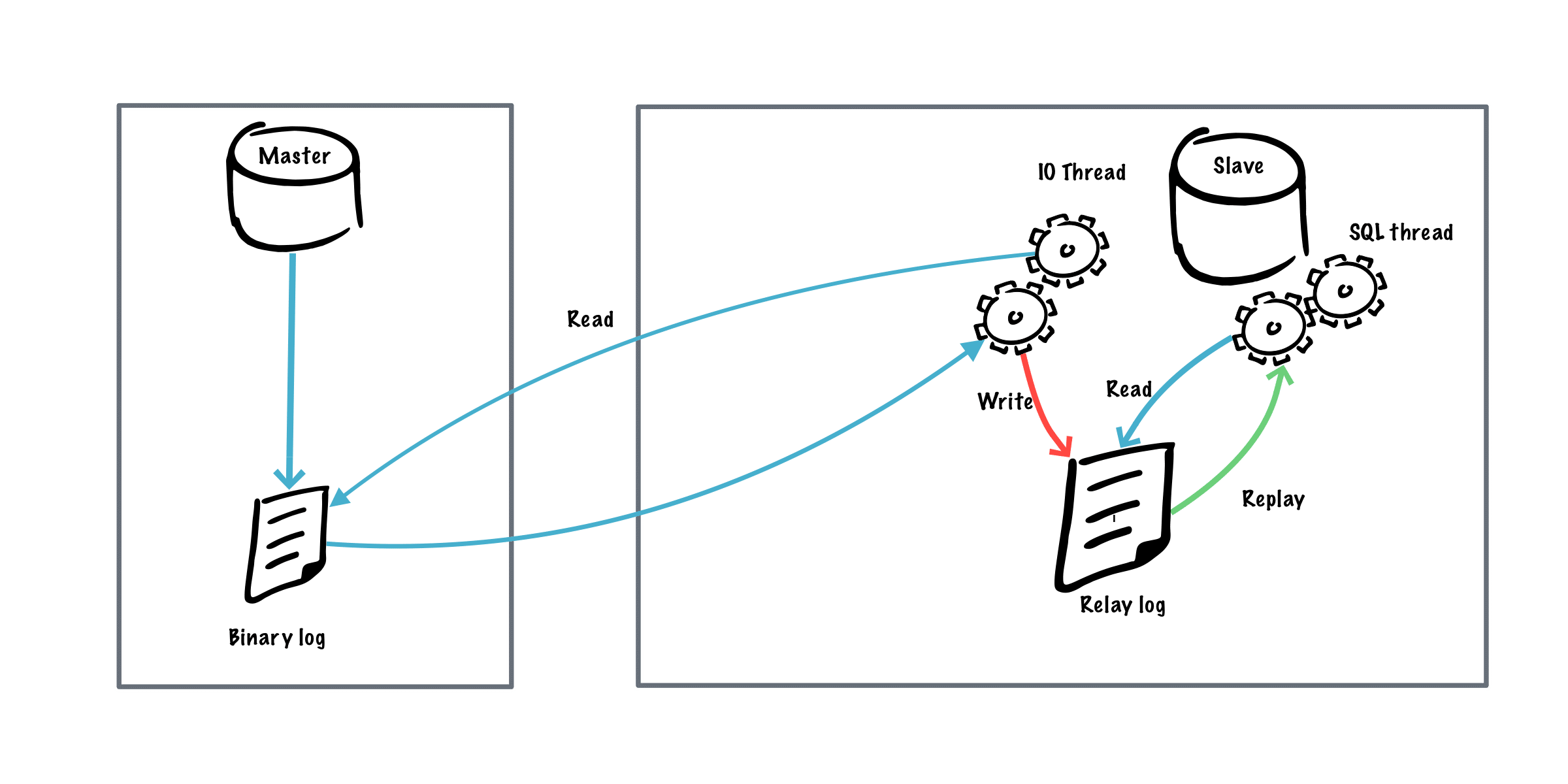
Here is how MySQL replication works.
- All database operations are copied to the master's binary log.
- Salves connect to the master and asks for the data.
- The slave servers get the masters binary log.
- Slaves then apply the binary log to its realy log.
- The relay log is read by the SQL thread process and it applies all the operations/data to the slave's database and its binary log.
TL;DR
- Replication can be Asynchronous or Semi-Synchronous
- In asynchronous replication write latency is lower as the writes are acknowledged by master locally.
- You can add more read replicas to improve the read throughput as your business grows.
- Replication is not an HA solution. If the master goes down, there needs to be some work done to get another slave as a master. So this strategy can be used for business systems which can afford a small interruption.
Use Cases
- This architecture is suitable for scaling MySQL with many read slaves.
- For backup strategy:
- Backup solutions like mysqldump can cause locking problems when the backup is being done.
- Replication allows you to reduce the load from the master as the replication slave will be involved in serving the application requests.
- For disaster recovery, replication is a great fit as you can set up a replication slave in a different region which asynchronously gets the master data. In an event of regional failures, we can bring up the database in a different region with the help of replication slave.
Here is a reference architecture of a replication cluster with ETL, reporting and backup use cases.
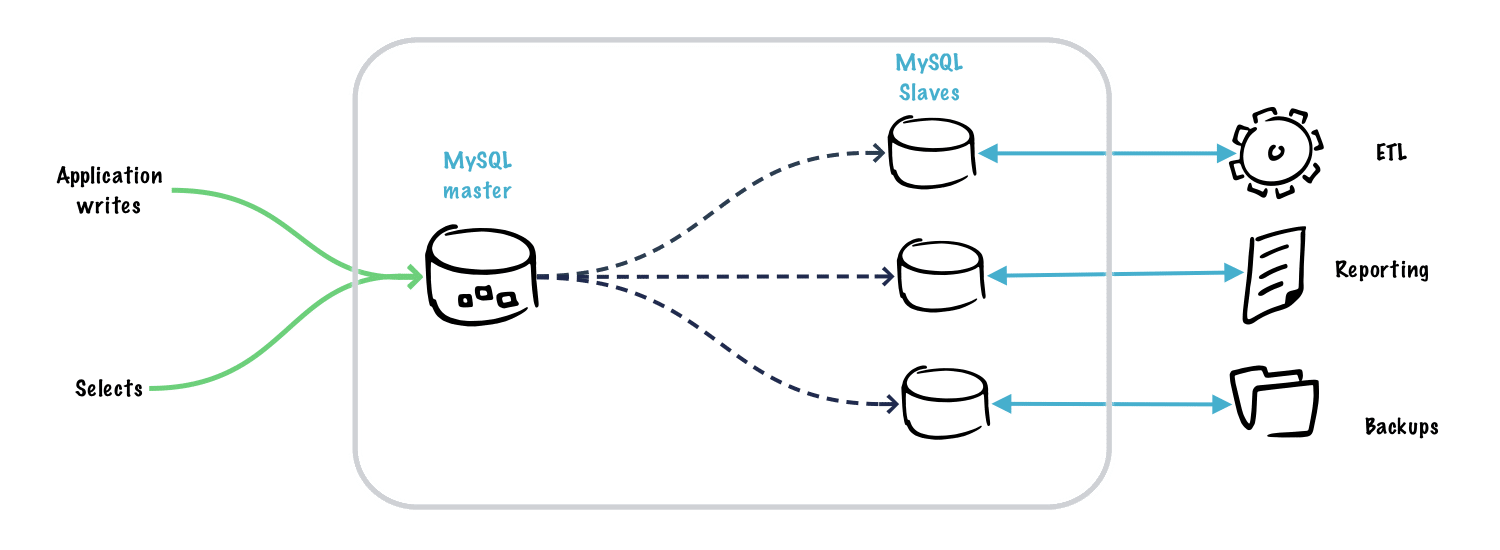
MySQL Master Slave Replication Setup
In this tutorial, we will explain the step by step guide for setting up a MySQL master-slave replication. For the tutorial purpose, we will use three Nodes for the MySQL replication cluster. One master node and two slave nodes.
Server Details:
Master Node: 10.128.0.11
Slave 01: 10.128.0.12
Slave 02: 10.128.0.13Prerequisites:
- Minimum 2 Nodes - one master & one slave. [Centos/Redhat 7 or greater]
- Connectivity to install packages using yum or through corp proxy if any.
- Root access to the servers.
- Each servers firewall should allow traffic on ports 22 and 3306.
Install MySQL Server on all three nodes
Let's install MySQL server on all the three nodes with specific configurations for master-slave replication.
Execute the following steps on all the three nodes.
Step 1: Install wget
sudo yum install wget -yStep 2: To install MySQL, we need to add the MySQL community repo which contains the actual MySQL community edition
Download the repo
wget https://dev.mysql.com/get/mysql57-community-release-el7-9.noarch.rpmInstall the repo
sudo rpm -ivh mysql57-community-release-el7-9.noarch.rpmStep 3: Install MySQL server.
sudo yum install mysql-server -yStep 4: Start and enable MySQL server.
sudo systemctl start mysqld
sudo systemctl enable mysqldStep 5: Get the default generated admin password from the mysqld.log file. This password has to be used in step 5 to change the default root password.
sudo grep 'temporary password' /var/log/mysqld.logStep 6: Setup MySQL password and other key configurations using the following command. All the steps are self-explanatory.
mysql_secure_installationConfigure MySQL Master Node
First, we will configure the master node with the required configuration.
The key configurations are
- Binding static IP address to MySQL server.
- Unique ID config for master. Each server in the cluster should be identified uniquely.
- Enable Binary log - It contains information about the data changes made to MySQL.
- Create a replication user that will be used by the slaves to replicate the data from the master.
Note: In this installation, MySQL data dir will default to /var/lib/mysql in the root file system. For production use cases, this path should be an external disk attached to the VM.
Step 1: Open /etc/my.cnf file.
sudo vi /etc/my.cnfStep 2: Add the following three parameters under the [mysqld] section and save it. Replace 10.128.0.11 your server IP.
bind-address = 10.128.0.11
server-id = 1
log_bin = mysql-binStep 3: Restart the MySQL server for the configurations changes to take place.
sudo systemctl restart mysqldStep 4: Check the MySQL status to make sure all the configurations are applied as expected without any errors.
sudo systemctl status mysqldStep 5: Login to MySQL server as the root user.
mysql -uroot -pStep 6: Create a user named replicauser with a strong password. This user will be used by the slaves to replicate the data from the master. Replace 10.128.0.11 with your master IP
CREATE USER 'replicauser'@'10.128.0.11' IDENTIFIED BY 'my-secret-password';Step 7: Grant privileges to the slave user for slave replication.
GRANT REPLICATION SLAVE ON *.* TO 'replicauser'@'%' IDENTIFIED BY 'my-secret-password';Step 8: From the MySQL prompt, Check the master status. Note down the file [mysql-bin.000001] and Position[706] parameters from the output. It is required for the slave replication configuration.
SHOW MASTER STATUS\GThe output would look like the following.
mysql> SHOW MASTER STATUS\G
*************************** 1. row ***************************
File: mysql-bin.000001
Position: 706
Binlog_Do_DB:
Binlog_Ignore_DB:
Executed_Gtid_Set:
1 row in set (0.00 sec)Configure MySQL Replication Slave Node
Execute the following steps in all the slaves.
Step 1: Add the same configurations as the master to the /etc/my.cnf file with the Slave Ip address and unique server ID.
bind-address = 10.128.0.12
server-id = 2
log_bin = mysql-binNote: If you more than one slave, make sure you replace the respective slave IP and add a unique server-id per slave.
Step 2: Restart the MySQL service.
sudo systemctl restart mysqldStep 3: Login to MySQL with root credentials.
mysql -uroot -pStep 4: Stop the slave threads using the following command.
STOP SLAVE;Step 5: Execute the following statement from MySQL prompt replacing the master IP [10.128.0.15], replicauser password [replicauser-secret-password].
Replace MASTER_LOG_FILE & MASTER_LOG_POS with the values, you got from step 8 in master configuration.
CHANGE MASTER TO MASTER_HOST='10.128.0.15',MASTER_USER='replicauser', MASTER_PASSWORD='replicauser-secret-password', MASTER_LOG_FILE='mysql-bin.000001', MASTER_LOG_POS= 706;Step 6: Now, start the slave threads.
START SLAVE;Step 7: Check the MySQL replication slave status.
SHOW SLAVE STATUS\GSlave_SQL_Running_State parameter will show the current slave status.
Test MySQL Master-Slave Replication
In this section, we will test master-slave replication.
On Master Server
Login to master mySQL CLI.
mysql -uroot -pCreate a database named testdb
CREATE DATABASE testdb;On Slave Server
Login to slave mySQL CLI.
mysql -uroot -pList the Databases. You should see the testdb database created from the master server.
show databases;Example, output.
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
| testdb |
+--------------------+Conclusion
If you are going to use MySQL master-slave replication in production, there are many other performance and MySQL parameters to be considered from a DBA perspective. Even if you have master-slave replication, a solid backup strategy should be in place for data restoration and disaster recovery.
So, are you planning to use MySQL master-slave replication in production? What is your existing setup?
