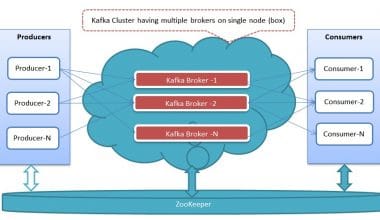
DDISTRIBUTED SYSTEMS Read More Setting up a Multi-Broker Kafka Cluster – Beginners GuidebydevopscubeOctober 25, 2016 Kafka is an open source distributed messaging system that is been used by many organizations for many use…
DDEVOPS Read More Service Discovery and Other Cluster Management Techniques Using ConsulbyPrabhu Vignesh Kumar RajagopalOctober 7, 2016 Consul is a cluster management tool from Hashicorp and it is very useful for creating advanced micro-services architecture.…
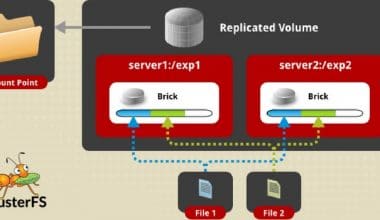
CCLOUD Read More How to Setup a Replicated GlusterFS Cluster on AWS EC2bydevopscubeOctober 6, 2016 GlusterFS is one of the best open source distributed file systems. If you want a highly available distributed…